- Introduction
- System architecture
- RedStone Node
- Providers registry
- Node monitoring tools
- RedStone cache layers (RedStone API)
- ArGue - Dispute resolution protocol [to be implemented]
- Accessing data
- Use cases for RedStone oracle
- Roadmap
- Need help?
RedStone is a data ecosystem that delivers fast and accurate financial information in a decentralised fashion.
- It is not sustainable to put all the pricing data into the Ethereum blockchain, as it wasn’t designed for this purpose. Sourcing data becomes enormously expensive with Gas price spikes. On a historically busy day on Ethereum, with a day average 500gwei Gas price, a single transaction may cost above $100, so if we persist every 10m across 30 sources, the daily bill will be more than $400k per one token
- To reduce costs current providers cover only a small subset of tokens and have low update frequency
- DeFi protocols cannot expand beyond a small set of assets and cannot offer advanced solutions like margin lending (which require higher update frequency)
RedStone offers a radically different design of Oracles catering for the needs of modern Defi protocols.
- Leverage Arweave blockchain as a cheap and permanent storage
- Use token incentives to motivate data providers to maintain data integrity and the uninterrupted service
- Use signed meta-transactions to deliver prices on-chain
- Although the data at RedStone is persisted on the Arweave chain, it could be used with any other blockchain
Initially, the most commonly utilised form for Oracle operations were the “two phase approach”:
- A contract submits a request for data to an Oracle Service;
- An Oracle Service sends back a response with data.
This simple and flexible solution was pioneered by Oraclize (now Provable) and Chainlink as Basic Request Pattern, but the main disadvantage to this approach is that the contract cannot access data immediately as it requires two separate transactions. Such design kills usability as the client needs to wait until the data comes to contract to see a result of an action. An even bigger problem is that fetching data is not atomic (meaning not in a single transaction) which means that synchronizing multiple contracts is complex, slow and ultimately kills interoperability.
Currently, the most popular approach taken by blockchains in an attempt to address the aforementioned issues is to persist all data directly on-chain, so that the information is available in the context of a single transaction. Protocols have also formed syndicates around the most popular oracles using common standardized configuration. Here, we listed some of popular Oracle solutions:
| Name of Project | Redstone | Chainlink | Band Protocol | DIA | API3 | Flux | Pyth |
|---|---|---|---|---|---|---|---|
| Blockchain of data storage | Arweave | Ethereum | Cosmos | Database host with oracles on different chains | DAO on Ethereum | NEAR | Solana |
| Number of assets supported | 1084 | 79 | 175 | 50 | No Info | No Info | No Info |
| Decentralised Governance | Yes | No | Yes | No | Yes | Yes | No |
| Multi-chain support | Yes | Yes | Dependent on Cosmos' Inter-Blockchain-Communication | No | Dependent in Parachain | Yes | No |
| Oracle Aggregator | Yes | No | No | Yes | Yes | Yes | No |
| New datafeeds requests from community | Yes | No | No | No | No | Yes | No |
| Supporting custom data feeds | Yes | No | No | No | No | No | No |
RedStone ecosystem could be divided into 3 main areas:
- Data provision responsible for fetching the data from external api, transforming to a common format, and persisting collected information.
- Implemented as → RedStone Node
- Data access responsible for serving data to end user by various means including web portal, http api, discord bots, on-chain feeds or 3rd party applications (like spreadsheet extensions)
- Web portal → RedStone App
- HTTP Api → RedStone Api
- Bots → Examples
- Data integrity responsible for enforcing high quality of data by incentivising providers with tokens for keeping their service and punishing them for outage and misrepresented data
- Concept → Argue protocol

- Data sources - provide data (like price information) via API
- DeFi protocols - consume aggregated and attested data
- Web integrations - utilise provided data to power apps like blockchain wallets, portfolio browsers, defi analytics sites
- Data providers - need to register with token stake and operate RedStone node which process and attest data
- End users - may browse pricing data and select providers using the web portal
- Juries - protect data integrity deciding if a price was manipulated
- RedStone node - fetches data from external sources via api, aggregates and attest information with a cryptographic key, broadcast the results and persist them on the Arweave blockchain
- Data cache - a module that holds data and makes it available to interested parties. Multiple services might implement it on various infrastructure to increase availability. It should achieve minimum latency and scale to handle large volume of requests
- Smart contracts api - it provides the data to on-chain protocols. Initially, we cover Arweave and EVM (ethereum) infrastructure. It minimizes the running (gas) costs and verifies signed data on-chain
- HTTP api - web based that serves information via REST api. It can power websites, node-js scripts and social media bots. There will be a dedicated java script wrapper that will abstract request formatting and error handling to make service easier to integrate
- Providers registry - an Arweave smart contract that manages provider's token stake, holds the manifest (SLA of pricing data) and allows checking historical performance (showing any data inconsistency and downtime)
- Dispute resolution protocol - a set of Arweave contracts allowing to challenge any existing pricing feed, and managing the dispute process enabling juries to vote for the verdicts
- Web portal - a web application that is an interface to browse data, check providers' statistics, see historical feeds with an option to raise a dispute and participate in the voting process
The token facilitates providing reliable and accurate information to blockchain networks from the external world.
Tokens are proven to be a very useful tool for achieving coordination in the distributed systems and aligning incentives of various actors. RedStone token facilitates data sharing ecosystem incentivising participants to produce, publish and validate data in a continuous and diligent way.
The end users who benefit from access to valuable information use tokens to reward providers that published these data. The exact fee and the subscription terms are at the discretion of the provider and depend on their effort, demand for data and potential competition.
Every provider needs to publish a Service Level Agreement describing the scope of data being served, the source of information, and the frequency of updates. In case a provider breaches the terms of service, there will be a penalty applied which is also denominated in tokens. In order to assure users that any further claims could be fully covered, providers need to put aside a certain amount of token and lock it for a period of time. These funds are labelled as a stake in the ecosystem and are an important factor for users to select the most reliable provider.
Because of the diverse nature of provided information, it will not always be possible to decide if a data was corrupted. Therefore, it will be necessary to have a fallback procedure to resolve any disputes about data quality. The process could be facilitated by tokens when juries will be rewarded for voting alongside the majority and punished for supporting a losing side.
At the early stage of development, the token could be distributed to providers to reward their availability and bootstrap the market before there is enough demand coming for data users.
RedStone Node is a core module in the RedStone ecosystem, which is responsible for fetching data from different sources and broadcasting it to the Arweave blockchain and the RedStone cache layer.
You can find the implementation of the redstone node in the github.com/redstone-finance/redstone-node repository.
In a cycle, we perform 3 major activities:
- Data fetching - gathering information from external sources
- Data processing - aggregating data and attesting with signature
- Data broadcasting - publishing data to users and persisting it on-chain
This component fetches pricing data and makes it available to end users. The process consists of the following steps:
- Data fetching - getting data from public or private api and transforming it the standard format
- Data aggregation - combining data from multiple sources to produce a single feed using median or volume weighted average
- Data attestation - signing data with the provider's cryptographic key
- Data broadcasting - publishing the data on publically available message board (like public firebase store)
- Data persistence - securing packaged data on the Arweave blockchain

Each group of subcomponent implements a generic interface and is interchangable with other implementations:
- Fetchers: connect to external api, fetch the data and transform it to the standard form Examples: coingecko-fetcher, uniswap-fetcher
- Aggregators: take values from multiple sources and aggregate them in a single value Examples: median-aggregator, volume-weighted-aggregator
- Signers: sign the data with the provided private keys Examples: ArweaveSigner, EthSigner
- Broadcasters: publish the data and signature Examples: FirebaseBroadcaster, SwarmBroadcaster
- Runner: execute the entire process in a loop
You can see a standard flow of the node iteration on the diagram below:

Currently, the price value is aggregated using the default median-aggregator. It works in the following way:

The price (ticker) is represented as a single JSON object
{
"id": "6a206f2d-7514-41df-af83-2acfd16f0916",
"source": {"coingecko": 22.05, "uniswap": 22.03, "binance": 22.07},
"symbol": "LINK",
"timestamp": 1632485695162,
"version": "0.4",
"value": 22.05,
"permawebTx":"g3NL...", // id of Arweave tx that includes this ticker
"provider": "I-1xz...", // Address of the provider's arweave wallet
"signature": "0x...",
"evmSignature": "0x..."
}Price tickers are aggregated per provider and timestamp and persisted on the Arweave chain. The provider is the tx sender.
{
"app": "Redstone",
"type": "data",
"version": "0.4",
"Content-Type": "application/json",
"Content-Encoding": "gzip",
"timestamp": 1632485616172,
"AR": 45.083730599999996
}We encrypt transaction data using the gzip algorithm to minimize transaction cost. We don't store a signature for each price on the Arweave blockchain, because each transaction is already signed using the default Arweave transaction signer.
[
{
"id":"a890a16a-ef4a-4e45-91fa-0e4e70f28527",
"source":{
"ascendex":41415.797549999996,
"bequant":41437.738515,
...
},
"symbol":"BTC",
"timestamp":1632486055268,
"version":"0.4",
"value":41416.892911897245
},
{
"id":"81f8c1cc-5472-4298-9d9d-ea48b226c642",
"source":{
"ascendex":2820.8997449999997,
"bequant":2823.8562225,
...
},
"symbol":"ETH",
"timestamp":1632486055268,
"version":"0.4",
"value":2821.3399649999997
},
...
]- Arweave storage - an average node spends ~0.00003AR/iteration, resulting in 0.00003 * 60 * 24 * 30 = 1.296AR/month assuming that the data fetching interval is 60 seconds. With the current AR price it is ~$55/month
- Node infrastructure - depending on a selected infrastructure and logs retention policy the Node infrastructure costs may be in the range from ~$10/month (simple EC2 machine on AWS) to ~$70/month (ECS cluster with connected Cloudwatch for logs querying)
- Cache layer - a provider can also configure their cache layer, wchich costs ~$5/month on AWS
Summing all up, the average monthly node operating cost is in the range from $70 to $130. Please also keep in mind that RedStone providers also need to pay some stake (min $100 in RedStone tokens) before running their node.
- Node.js (v14 or higher) and
yarn - Arweave wallet (> 0.1AR)
yarn installManifest is a public JSON file that defines the provider's obligation regarding the data that they provide. It sets fetching interval, tokens, sources and other public technical details for the provided data.
There are 2 options for loading manifest in the redstone-node:
- Loading from JSON file. This option is preferred for local runs and experiments
- Loading from SmartWeave contracts
You can use any of our ready-to-use manifests. For example:
- main.json - 1000+ tokens, used by the main redstone provider
- rapid.json - 10 most popular tokens, used by
redstone-rapidprovider - coinbase.json - 20 tokens, uses only coinbase fetcher
You can also prepare your own manifest and place it inside the manifests folder. The manifest file should be named using kebab case, i.e: manifest.json, good-manifest.json, or your-source.json.
You can also publish your manifest to the Arweave smart contracts.
Here is the structure of the manifest file:
| Param | Optionality | Type | Description |
|---|---|---|---|
| interval | required | Number | Data fetching interval in milliseconds |
| priceAggregator | required | String | Aggregator id. Currently only median aggregator is supported |
| defaultSource | optional | String[] | Array of fetcher names that will be used by default for tokens that have no specified sources |
| sourceTimeout | required | Number | Default timeout in milliseconds for sources |
| maxPriceDeviationPercent | required | Number | Default maximum price deviation percent for tokens. It may also be set for each token separately |
| evmChainId | required | Number | EVM chain id, that will be used during EVM price signing. Pass 1 if you're not sure, it will point to the Ethereum Mainnet. |
| tokens | required | Object | Object with tokens in the following format: { "TOKEN_SYMBOL": { "source": ["source-name-1", "source-name-2", ...], "maxPriceDeviationPercent": 25 }, ... }. Note that source and maxPriceDeviationPercent params per token are optional. This is also a correct tokens configuration: { "TOKEN_SYMBOL_1": {}, "TOKEN_SYMBOL_2": {} } |
You can find a list of available sources along with its stability details in the RedStone Web app: app.redstone.finance/#/app/sources.

Config file is a private file created by a provider. It contains the following details required by the redstone-node:
| Param | Optionality | Description |
|---|---|---|
| arweaveKeysFile | required | path to the arweave wallet (for relative paths it assumes that you are in the project root folder) |
| minimumArBalance | required | minimum AR balance required to run the node |
| useManifestFromSmartContract | optional | if set to true , manifest will be loaded from Arweave Smart Contracts |
| manifestFile | optional | path to the manifest file |
| addEvmSignature | optional | if set to true, EVM signature will be added to each price for each asset |
| credentials | required | object with credentials for APIs and private keys |
| credentials.ethereumPrivateKey | required | Ethereum private key that will be used for price data signing |
| credentials.yahooFinanceRapidApiKey | optional | API key for the api-dojo-rapid fetcher |
You should place your config file inside the .secrets folder, which is included in .gitignore. You should never publish this file.
Please note, the instruction below is for Unix operating systems (like Linux or MacOS). If you use Windows, we recommend running the redstone node in a Docker container.
yarn start --config PATH_TO_YOUR_CONFIGWe recommend redirecting output to some log file(s), for example:
yarn start --config PATH_TO_YOUR_CONFIG > my-redstone-node.logs 2> my-redstone-node.error.logsYou can also enable JSON mode for logs to simplify the log analysing later.
To do this append ENABLE_JSON_LOGS=true to the node running command:
ENABLE_JSON_LOGS=true yarn start --config PATH_TO_YOUR_CONFIG > my-redstone-node.logs 2> my-redstone-node.error.logsYou can run a local redstone-node in docker.
-
Prepare your Dockerfile based on ./Dockerfile. Name it
Dockerfile.my-redstone-nodeand place it in the project root folder. -
Build a docker container with redstone-node
docker build -f Dockerfile.my-redstone-node -t my-redstone-node .- Run the docker container
docker run -it my-redstone-nodeThere are 2 main things that your node needs to do:
To verify if prices are being saved on Arweave, navigate to https://viewblock.io/arweave/address/YOUR_ADDRESS.
You should see some transactions with the tag app and value Redstone ~20 minutes after the node running.
You can simply open this URL https://api.redstone.finance/prices?provider=YOUR_ADDRESS in browser and see if it returns signed data. Don't forget to replace YOUR_ADDRESS with your Arweave wallet address
We've also implemented an automated monitoring system for nodes. It will be described below in the Node monitoring tools section.
RedStone node environments (modes) help to differentiate node configuration for different purposes.
There are 2 main environments, that are already created in the RedStone node:
- PROD (should be used for real long-term node deployment)
- LOCAL (should be used for tests, development and experiments)
Production environment automatically enables services, that are not useful in local environment, such as:
- error reporting
- performance tracking
- publishing on Arweave
Environments can be configured using environment variable MODE. Set it to PROD to run redstone node in the production environment or to LOCAL to run redstone node locally.
- ENABLE_JSON_LOGS - set this variable to
trueto enable logging in JSON format. It is recommended to set it totrueif you run the node in the production environment. - PERFORMANCE_TRACKING_LABEL_PREFIX - human-friendly name that will be appended to the performance tracking labels. (Examples:
mainforredstoneprovider,stocksforredstone-stocks,rapidforredstone-rapidprovider)
Dockerfiles are used to build docker images, which are usually executed in the Production environment. To configure the production environment, ENV instruction should be added to a Dockerfile.
ENV MODE=PROD
ENV ENABLE_JSON_LOGS=true
ENV PERFORMANCE_TRACKING_LABEL_PREFIX=stocksPerformance tracking is enabled in the production environment and tracks by default all of the most important processes during each node iteration. Currently we save performance data in AWS cloudwatch, where it can be analysed using convenient chart tool:

We track performance for the following processes:
- processing-all
- balance-checking
- fetching-all
- fetching-[SOURCE_NAME]
- signing
- broadcasting
- package-broadcasting
- transaction-preparing
- arweave-keeping
If you set PERFORMANCE_TRACKING_LABEL_PREFIX environment variable, its value will be appended to the performance tracking labels (for example: rapid-processing-all for PERFORMANCE_TRACKING_LABEL_PREFIX=rapid)
We use the jest framework for automated testing. Test files are located in the test folder. We test each fetcher separately (fetchers tests are located in the test/fetchers folder). We also have integration tests in the test/integration folder and tests for separate modules:
- EvmPriceSigner.spec.ts
- ManifestParser.spec.ts
- median-aggregator.spec.ts
- PricesService.spec.ts
You can run the tests in the following way:
yarn testWe will use words source and fetcher. Сonsider them to be synonymous.
First, you should select a name for your source.
It should use kebab case, for example: source, good-source, the-best-source.
Source name must be unique, because it will unambiguously identify your source.
Create a folder with a name of your fetcher in src/fetchers. Place the code of your fetcher inside of this folder and update src/fetchers/index.ts file to export your source. For more information check out BaseFetcher code and implementation of other fetchers, like coingecko, coinbase, and ecb.
We strongly recommend implementing tests for your fetcher. It's generally a good practice and it will help you to avoid silly bugs in your code. You can find examples of tests for other fetchers in the test/fetchers folder.
- Create a manifest with the name of the newly added fetcher and place it in the manifests folder
- [Optional] If the source should be used in the main redstone provider, run
node tools/manifest/generate-main-manifest.js
Sources config file is used in the RedStone web app. If you want your source to be visible there you should add it to config and update the app appropriately.
- Add source details to the
tools/config/predefined-configs/sources.jsonfile - Run
yarn build. It is required bygenerate-sources-config.jsso it can work correctly - Run
node tools/config/generate-sources-config.jsto generate sources config. It will be saved tosrc/config/sources.json - Download logo for the newly created source
- You can simply download it in browser and save as
<SOURCE_NAME>.<IMG_EXTENSTION> - Or you can run
node tools/cdn-images/download-source-logos.js, but it will download logos for all sources
- You can simply download it in browser and save as
- Upload the source logo to RedStone CDN (manually through AWS S3 web interface)
- Run
node tools/cdn-images/update-sources-config.jsto replace logo urls in sources config with redstone CDN urls - Update
redstone-nodedependency in redstone-app for being able to use the new source config file
Tokens config file, which is located in src/config/tokens.json, is used in the RedStone web app and redstone-api. If you want your token to be accessible through the redstone-api npm module you should add it to the config.
- Add token details to
tools/config/predefined-configs/tokens.json - Run
node tools/config/add-new-tokens-from-predefined-config.js - Upload the token logo to RedStone CDN, so it is publicly accessible at
https://cdn.redstone.finance/symbols/<TOKEN_NAME_LOWER_CASE>.<IMG_EXTENSION></IMG_EXTENSION> - Run
node tools/cdn-images/update-tokens-config.jsto replace logo urls in tokens config with redstone CDN urls - Update
redstone-nodedependency inredstone-api,redstone-appand other packages wheretokens.jsonis used.
Providers registry is an Arweave smart contract that manages provider's token stake, holds the manifest (SLA of pricing data) and allows checking historical performance (showing any data inconsistency and downtime).
You can find the source code of providers registry smart contract here.
This contract:
-
Tracks profile data of all the currently available RedStone data providers.
name description id unique id of a given data provider name human-readable name of the data provider description description of the provided data url url to the data provider's website urlImg url to an img with provider's logo -
Keeps current and historical manifests data for all the registered nodes.
-
Allows updating of a given provider's manifest.
-
Allows updating of a given provider's meta-data.
-
Allows adding and removing providers.
-
Allows configuring provider's admin accounts (i.e. account that are allowed to change provider's manifest and meta-data).
Contract is implemented as an Arweave SmartWeave contract and is currently available under OrO8n453N6bx921wtsEs-0OCImBLCItNU5oSbFKlFuU address.
Most of the administrative operations can be also performed using a dedicated user interface in app.redstone.finance.
List of available data providers loaded from the Arweave:

Details of the provided data for the selected provider (selected provider: RedStone):

Provider's manifests history loaded from the Arweave:

UI for the manifest creation and updating:

In order to perform any operation, you need to connect the provider's wallet first (using ArConnect Browser extension).
There are also currently two other contracts implemented:
- contracts-registry contract - this contract keeps track of all the RedStone's SmartWeave contracts and allows to abstract a given contract's logical name from its current Arweave tx address. It also allows versioning of the contracts. We also post the Arweave transaction id of the contract here to make web integrations easier.
- token contract - this a work-in-progress of a RedStone Token contract, which is an implementation of a Profit Sharing Token with additional features - like
"deposit" on another contract and wallet id (e.g. provider can stake some tokens on his own node registered in
providers-registrycontract). Due to the current technical limitations of the SmartWeave SDK, the information about the deposit is currently stored in the "token" contract - which is inconvenient from the "withdraw" operation perspective - as this operation has to first ask the dependent contract how many tokens can be withdrawn - in order to this, dependent contract has to then first read the "token" contract state and check how many tokens are deposited. This complicated flow will be greatly simplified when our new RedStone SmartContracts SDK will allow performing "interactWrite" operations between contracts - i.e. changing state of one contract from the source code of another contract.
- place your JWK key in .secrets/redstone-jwk.json
- run the following command
node src/tools/providers-registry.api.js addManifest "<PATH_TO_MANIFEST>" "<UPDATE_COMMENT>" 0 false
It's insanely important for oracles to provide high quality data without interruptions. So, the node operators need to monitor their nodes and immediately fix any potential problems.
That's why we've implemented a special app redstone-node-monitoring, which is executed in a loop and automatically verifies if a selected node regularly publishes new data to the RedStone cache layer and the Arweave blockchain. In each loop iteration multiple checkers are executed. And if any of these checkers fail then the error is reported.

Checker - a module responsible for data integrity checking. It can check the number of saved data points during the last 5 minutes or the timestamp of the latest saved data point.
Implemented checkers:
- ArPriceReturnedRedstoneRapid
- ArPriceReturned
- ArweaveTimestampDelay
- HistoricalPricesReturned
- StockPricesReturnedRedstoneStocks
- TimestampIsCloseToNowRedstoneRapid
- TimestampIsCloseToNow
Reporter - a module responsible for error/warning reporting. For example, it can notify a node operator via email, SMS or discord. It can also save a notification to a text file. Currently we send email notifications to our developer team and save logs in AWS Cloudwatch.
You can find more details about running or extending this monitoring service in the redstone-node-monitoring GitHub repo.
The data signed by a provider should be broadcasted to multiple cache layers in order to ensure the data accessibility and to keep the whole system more decentralised, stable and resistant to attacks. By default, redstone-node uses a single RedStone API cache layer. However each data provider is able to update the broadcasting logic in their node and enable broadcasting to several cache layers.
The cache layer code is Open Source and can be downloaded from our GitHub. You can find more details about its architecture and the deployment process below.
RedStone cache layer is a Node.js Express app, which allows users to save and query signed data points (currently pricing for assets) in MongoDB.
We always implement tests for all the core modules of the RedStone ecosystem, including the cache layer app. You can run tests in the following way:
# Install dependencies
yarn install
# Run tests
yarn testWe run our instance of the cache layer on AWS. However, it can be deployed on GCP, Azure, Heroku or any other service. You should set up a mongoDB instance (the simplest way to do this is using Mongo Atlas). Then you should place .secrets.json file into the root folder of the repo and run the app using the yarn dev command.
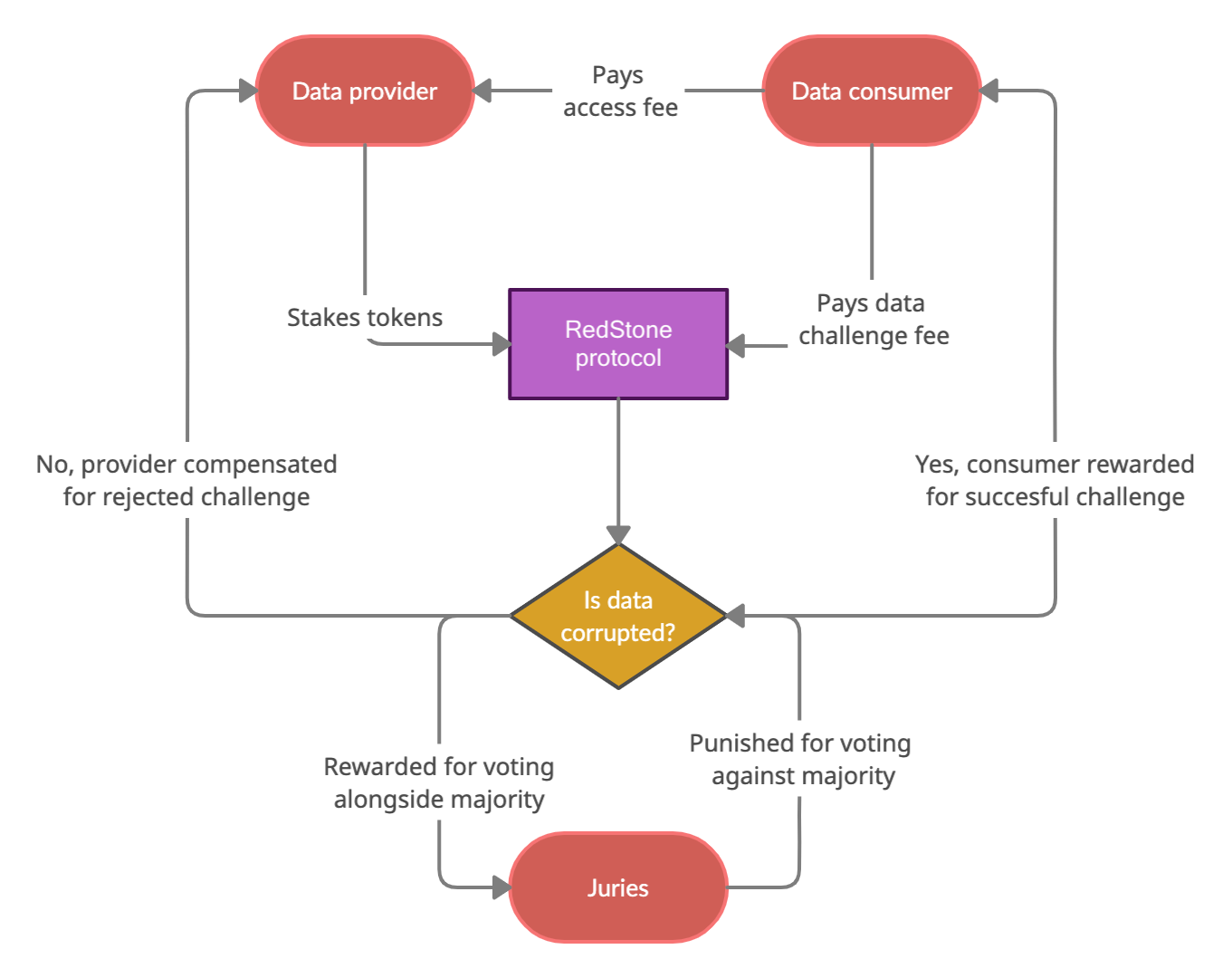
Decentralised data feeds have many advantages over centralised competitors. They are more secure, lacking a central point of failure and more censorship-resilient because of diversified governance. However, it’s not trivial to manage data integrity and accuracy without a central point of control.
ARgue protocol enables high data integrity preserving the benefits of keeping a fully decentralised and diverse set of data providers. Users are incentivised to report problems with data quality by opening a dispute. Disputes are resolved by a panel of jurors who vote by staking tokens. The consensus is based on the majority rule, where voters are rewarded for voting alongside others and penalised for being outliers.
The majority rule is the most common strategy for reaching coordination in a decentralised environment. It was researched as a part of game theory studies in the 60s, and the current implementations are based on the work of Thomas Schelling and his idea of the focal point described in the book Strategy and Conflict.
One of the adaptations of this idea was drafted by Vitalik Buterin in 2014 as a Schelling Coin concept. It was also proposed as an architecture for the Ethereum Price Feeds: “For financial contracts for difference, it may actually be possible to decentralize the data feed via a protocol called SchellingCoin” (from the Ethereum whitepaper). However, the network congestion, high gas price and the extreme storage cost of the Ethereum Virtual Machine rendered the solution impractical at the current level of technology.
New generations of blockchains like Arweave could finally make the implementation of Schelling-point based algorithms economically feasible due to the cheaper storage and low contracts execution cost. The challenging part is setting the system parameters to keep the user friction as low as possible and reduce the voting requirement while maintaining the high quality of decisions. Hopefully, the recent simulations done by the Redstone team prove that even a small percentage of expert jurors could produce high-quality results when the incentives are properly set up (see the simulations of TCR-based decision model presented during EdCon Paris 2019).
The dispute is a multi-stage process that involves two main counter-parties: a challenger, who initiates the dispute, a provider, who originated the challenged data entry and a jury panel that makes the final decision. The actors are incentivised to participate with potential token rewards. All of the stages of the process are described below:
A data provider may deposit collateral as a signal to the users that there is a strong financial commitment to maintaining the quality of data. The higher the collateral means the higher potential reward for the challenger but it also translates into a higher fee to open a dispute.
Anyone could open a dispute providing he can deposit an initial stake which is proportional to the provider’s deposit. There is also a minimum stake value introduced to avoid spamming. The challenger stake is locked until the dispute is settled.
Jurors vote by staking their tokens either to support or reject the dispute. The maximum amount of tokens that could be staked is limited by an additional parameter called "voting capacity" (see the challenges section for more details). Voting lasts until a deadline which is typically a week.
If a required quorum is reached before the deadline, the choice with the highest amount of token staked is called a verdict. A party that is not satisfied with the verdict may submit an appeal during the appeal window (typically 3 days). If there is no appeal the verdict is considered final and the settlement is executed.
An appeal submission requires doubling the current challenge fee. It will restart the voting and double the required quorum. If the quorum is already above 50% it is impossible to submit another appeal and the current verdict is considered final.
After the verdict is final the winning party receives a reward which is taken either from a challenger fee or provider deposit. Part of the reward is distributed to the judges. There is also an internal redistribution of tokens among the judges. Those supporting the majority choice get part of the tokens staked on the losing side. The jurors who were on the winning side also increased their voting capacity. The results are persisted on the permaweb and could be used as a base for reputation score for providers, watchers and jurors.
Here is the flowchart showing the dispute flow:

The list below contains system parameters used to manage the dispute resolution process. The values are based on the similar existing models and simulations, therefore they might require tuning after the deployment in the real-world environment. The update could be managed by decentralised governance in the form of token weighted voting by all the stakeholders.
| Parameter | Default value | Description |
|---|---|---|
| voting duration | 7 days | A period when jurors are able to vote on the dispute |
| appeal window | 3 days | A time when the losing side could submit an appeal |
| base quorum | 5% | A minimum percentage of total token supply that needs to be staked during the voting |
| escalation factor | 2x | A multiplier that is applied both to the quorum and challenger fee after the appeal |
| min challenge fee | $100 worth of Redstone Tokens | A minimum amount of tokens that need to be staked by the watcher (challenger) |
| judgement fee | 20% | Part of the voting stake (from challenger or provider) that is redistributed to the jurors |
| voting penalty | 10% | Part of the losing jurors’ stake that is redistributed to the one who supported the final verdict. |
The diagram below presents smart-contracts with their connections and descriptions below.

Tribunal - a master contract orchestrating the dispute process and linking all the dependent components
Disputes Catalog - a contract storing current and past disputes with their metadata, status, stake and references to all the parties involved
Judges Registry - a contract keeping a track of jurors with their voting capacity
Voting engine - a contract containing the logic for voting rules, describing the procedure and implementing possible privacy-preserving solutions
Verdict executor - a contract authorised to reallocate tokens according to the results of voting and set the final dispute outcome
Staking token - a profit-sharing token that enables staking on a specific topic, in this context, on the dispute-decision key
Many blockchain voting systems suffer from voters’ apathy as governance proposals cannot attract the required quorum. Redstone mitigates this problem by introducing a gradual voting scheme. For the first voting on a dispute, there is a low quorum that increases with every appeal. This allows to resolve uncomplicated cases with little friction but allows for proper verification and majority voting if the case is complex enough.
Decentralised voting systems use tokens to express voting power. Although the freedom to trade is a necessary feature of every token, buying a large amount of tokens just before important voting could derail the entire system. Not addressing this point was one of the most criticised vulnerabilities of the Aragon court. Redstone mitigates the issue by introducing another dimension to token ownership called holding capacity. It represents the maximum amount of tokens a juror could hold that can increase only as a result of making correct decisions. This ensures that jurors could gradually earn their voting power and the system is immune to short-term votes buying
Jurors benefit from participating in the judgement, therefore there may be a tough competition to vote for a high-stake dispute. To prevent front-running and guarantee an equal right to vote for all the token holders, Redstone plans to implement a random-based selection process. The chances to be selected as a judge are proportional to the voting capacity, a variable that describes that increased gradually with every successful choice made by a juror. This ensures that the best arbiters will have the most opportunities to resolve disputes.
In most of the cases, public voting will be sufficient and the most cost-effective method to judge the dispute. However, in special cases involving high-stake or confidential content, there could be a need for a privacy-preserving process. We could easily extend the voting mechanism implemented by the Tribunal contract to support either a two-phase commit-reveal process or use zero-knowledge proofs of jurors’ decision.
RedStone data providers have an obligation to keep the broadcasted data on the Arweave blockchain to guarantee the data accessibility and power the dispute resolution mechanism. The signature that is attached to the broadcasted data allows to prove the data ownership.
Therefore, if there is a data package that is signed by a data provider and not persisted on the Arweave blockchain, a dispute can be raised.
You can see a detailed scheme of a dispute reasoning on the diagram below:

Putting data directly into storage is the easiest way to make information accessible to smart contracts. However, the convenience comes at a high price, as the storage access is the most costly operation in EVM (20k gas for 256bit word ~ $160k for 1Mb checked 30/08/2021) making it prohibitively expensive to use.
redstone-flash-storage implements an alternative design of providing data to smart contracts. Instead of constantly persisting data on EVM storage, the information is brought on-chain only when needed (on-demand fetching). Until that moment, the data remains available in the Arweave blockchain where data providers are incentivised to keep information accurate and up to date. Data is transferred to EVM via a mechanism based on a meta-transaction pattern and the information integrity is verified on-chain through signature checking.
At a top level, transferring data to an EVM environment requires packing an extra payload to a user's transaction and processing the message on-chain.

- Relevant data needs to be fetched from the RedStone api
- Data is packed into a message according to the following structure

- The package is appended to the original transaction message, signed and submitted to the network
All of the steps are executed automatically by the ContractWrapper and transparent to the end-user
- The appended data package is extracted from the
msg.data - The data signature is verified by checking if the signer is one of the approved providers
- The timestamp is also verified checking if the information is not obsolete
- The value that matches a given symbol is extracted from the data package
This logic is executed in the on-chain environment and we optimised the execution using a low-level assembly code to reduce gas consumption to the absolute minimum
We work hard to optimise the code using solidity assembly and reduce the gas costs of our contracts. Below there is a comparison of the read operation gas costs using the most popular Chainlink Reference Data, the standard version of Redstone PriceAware contract and the optimised version where provider address is inlined at the compilation time. The scripts which generated the data together with results and transactions details could be found in our repository.

The redstone-flash-storage tool can be installed from the NPM registry:
# using npm
npm install redstone-flash-storage
# or using yarn
yarn add redstone-flash-storageYou can find more details and documentation in its GitHub repo: github.com/redstone-finance/redstone-flash-storage
Data provided by current RedStone providers is accessible in the RedStone web app: app.redstone.finance.


Redstone HTTP API allows to fetch data from the RedStone cache layer.
Base url: https://api.redstone.finance
More details about RedStone HTTP API: https://api.docs.redstone.finance/http-api/prices
We've also implemented a Javascript library for fetching RedStone data from the RedStone cache layer.
It can be installed from the NPM registry:
# using npm
npm install redstone-api
# using yarn
yarn add redstone-apiYou can find much more details and API documentation using the links below:
- Documentation: https://api.docs.redstone.finance/
- Source code: https://github.com/redstone-finance/redstone-api
- NPM module: https://www.npmjs.com/package/redstone-api
You can fetch all the data provided by RedStone providers directly from the Arweave blockchain using its graphql endpoint: https://arweave.net/graphql.
Please keep in mind that you should decompress the transaction data using the gzip algorithm after fetching.
Example query to fetch RedStone transactions IDs and tags
{
transactions(
tags: [
{ name: "app", values: "Redstone" }
{ name: "type", values: "data" }
{ name: "Content-Type", values: "application/json"}
{ name: "version", values: "0.4" }
]
block: { min: 775000 }
owners: ["I-5rWUehEv-MjdK9gFw09RxfSLQX9DIHxG614Wf8qo0"]
first: 50
) {
edges {
node {
tags {
name
value
}
id
}
}
}
}
You can learn more about fetching data from the Arweave blockchain at: https://gql-guide.vercel.app/
Thanks to its scalability, the RedStone protocol creates unlimited possibilities for the DeFi protocols. You can find some common use cases for the RedStone data ecosystem below.
Less popular tokens face difficulties trying to provide their price data on-chain. It doesn't make an economical sense for today's oracles, because the revenue from the provided data would be lower than its providing costs.
RedStone already provides data for more than 1000 different crypto assets. Yet our technology allows to provide even 5 times more data spending just a small part of the other oracle's operating costs.
Thanks to its scalability and much lower storage costs, RedStone protocol makes it possible to improve current DeFi protocols using more advanced financial data, like:
- interest rates
- volatility
- liquidity
- and many more
Historical data have lower economical value for DeFi protocols than the real-time data. That's why they are not supported by most of today's oracles. Fortunately, the RedStone protocol allows to use them on-chain as well.
There are unlimited possibilities for the data types that can be provided on-chain through the RedStone protocol, including financial derivatives, voting data, political decisions, climate conditions, sport competition results, and much more.
RedStone-stocks provider is a good example, as it already provides versatile data, including pricing data for:
- Stocks
- Currencies
- ETFs
- Grains
- Energies
- Metals
- Livestocks
You can find the estimated plan of Redstone oracle development activities with the corresponding timing in the table below. We don’t include a few things that we do continuously:
- Improving the codebase stability
- Extending monitoring scripts and error reporting
- Stress testing infrastructure with load and PEN tests
- Connecting new sources and data feeds based on the feedback from users and stakeholders (for example NFT pricing, advanced financial data, voting results, climate data, sport…)
| Description | Timing | Notes |
|---|---|---|
| Support for multiple broadcasters | Q4 2021 | The data signed by a provider will be broadcasted to multiple cache layers in order to ensure data accessibility and to keep the whole system more decentralised, stable and resistant to DDOS attacks. |
| Backup nodes | Q4 2021 | To ensure node stability we’ll prepare implementation of backup nodes. A backup node will be running independently from the master node. It will repeatedly check if the main node is working properly and if not - it will switch to the “master” mode and will start to operate as a standard node until the original node comes back. |
| Encrypted content | Q4 2021 | We’ll add the ability to persist encrypted content allowing providers to deliver non-public information. |
| Auditing redstone-flash-storage | Q4 2021 | We’ll invest significant resources to ensure the security of the redstone-flash-storage module (e.g. ordering independent smart contracts audits) |
| Onboarding at least 5 data providers (node operators) | Q4 2022 | Growth |
| Integrate with at least 5 data consuming protocols to pilot the solution | Q4 2022 | Growth |
| Scaling supported assets to 5K | Q1 2022 | At 08.10.2021 the Redstone oracle supported ~1.1K assets. By enabling support for 5K assets, RedStone will become the confident leader in the oracle space in terms of the data amounts, outrunning the current leader (umbrella network that supports 1200 data pairs) |
| Improving the aggregator mechanism | Q1 2022 | Implementing a weight-median-aggregator (weighted by source trust) |
| UI for no-code node configuration | Q1 2022 | The idea is similar to the Mongo Atlas. We’ll offer some kind of RNAAS (Redstone node as a service). People will be able to run their nodes by configuring it in the browser and paying some required stake. We’ll try to design it in a way where we won’t have access to their private keys. |
| Allowing to provide any kind of data | Q1 2022 | We’ll extend our infrastructure to process complex data structures apart from simple pricing information |
| Allowing to “connect any API to blockchain” | Q1 2022 | We’ll implement a UI for running a simple node based on the provided API url and some transformation. The UI will create under the hood a standalone node with a new fetcher that will fetch data from the provided API URL and transform the data using the provided transformation. |
| Connecting api responses proof mechanism (e.g. using TLS Notary) | Q2 2022 | We’ll research the mechanism of proving the received responses from external APIs using TLS protocol. So that a data provider will be able to prove that he/she has got a given response from a given url at a given timestamp. This proof may help the data provider in disputes later. Of course, it will work only for urls that start from https. |
| Implementing the dispute protocol | Q2 2022 | We’ll implement the SmartWeave contracts and the UI for the dispute resolution protocol. We’ll invest significant resources to ensure the contracts security by ordering independent audits and scrupulous testing. |
| Onboarding at least 10 data providers (node operators) | Q2 2022 | Growth |
| Integrate with at least 10 data consuming protocols to pilot the solution | Q2 2022 | Growth |
| Onboarding at least 10 independent broadcaster operators | Q3 2022 | Decentralisation |
| Making the node running process as easy as possible (Preparing AWS / GCP / Azure / Heroku configuration templates, preparing the first-class documentation, continuous interaction with the community and rewarding the most active community members) | Q4 2022 | Decentralisation |
This documentation is a living file with constant updates. If you find something unclear, would like to share suggestions or ask questions, join our Discord channel or send us a note via contact form. We're always happy to get feedback and improve our products.
- Discord: https://redstone.finance/discord
- E-Mail: dev@redstone.finance
Thank you for your trust and choosing RedStone Oracle!
RedStone Team