






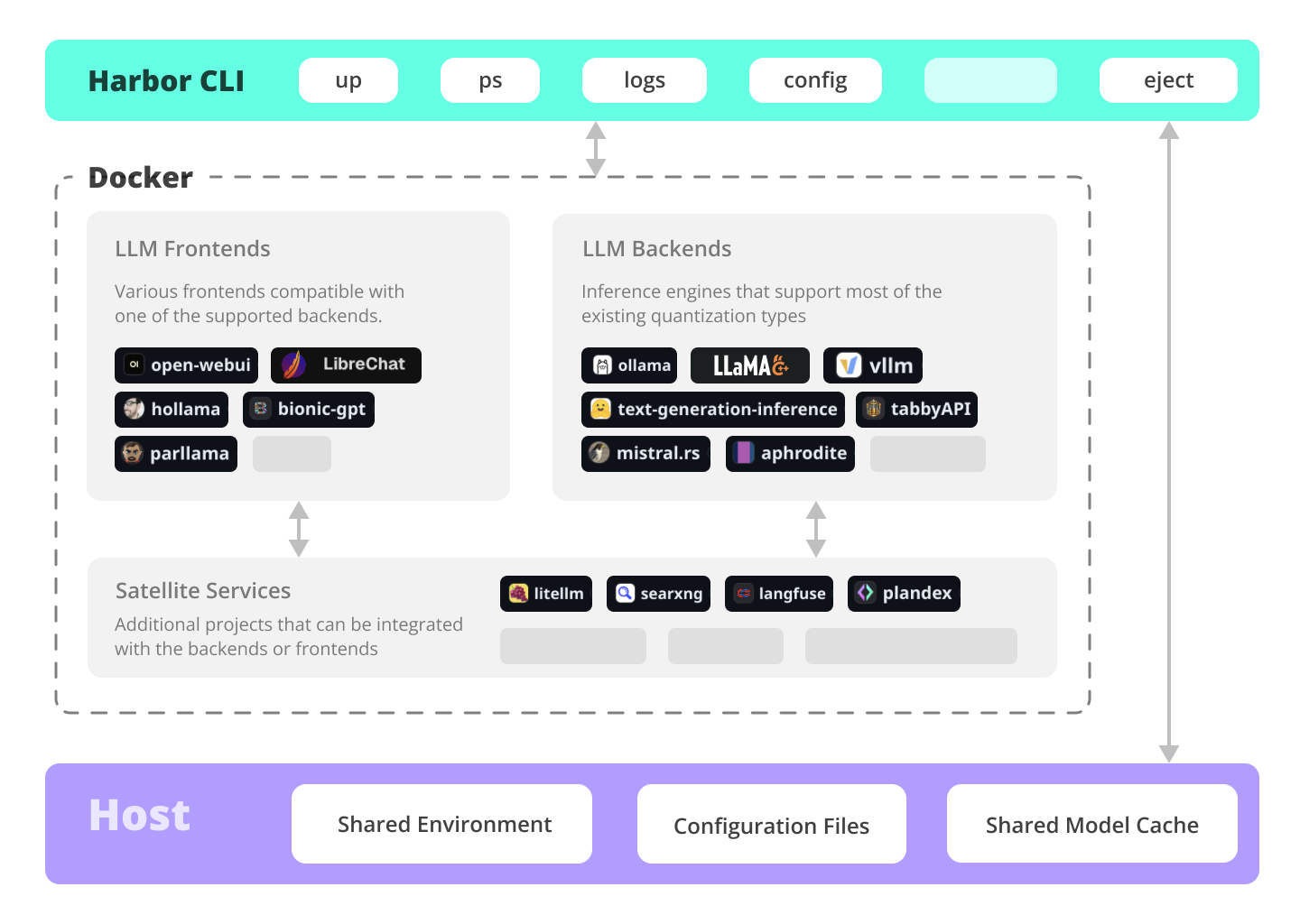
Effortlessly run LLM backends, APIs, frontends, and services with one command.
Harbor is a containerized LLM toolkit that allows you to run LLMs and additional services. It consists of a CLI and a companion App that allows you to manage and run AI services with ease.

| What | Overview | Links |
|---|---|---|
| Local LLMs | Run LLMs and related services locally, with no or minimal configuration, typically in a single command or click. | Harbor CLI, Harbor App |
| Cutting Edge Inference | Harbor supports most of the major inference engines as well as a few of the lesser-known ones. | Inference Backends |
| Talk to your LLM | Setup voice chats with your LLM in a single command. Open WebUI + Speaches | harbor up speaches |
| Generate Images | ComfyUI + Flux + Open WebUI integration. | harbor up comfyui |
| Local Perplexity | Harbor includes SearXNG that is pre-connected to a lot of services out of the box. Connect your LLM to the Web. | harbor up searxng |
| LLM Workflows | Harbor includes multiple services for build LLM-based data and chat workflows: Dify, LitLytics, n8n, Open WebUI Pipelines, FloWise, LangFlow | harbor up dify |
| Chat from the phone | You can access Harbor services from your phone with a QR code. Easily get links for local, LAN or Docker access. | harbor qr, harbor url |
| Chat from anywhere | Harbor includes a built-in tunneling service to expose your Harbor to the internet. | harbor tunnel |
| LLM Scripting | Harbor Boost allows you to easily script workflows and interactions with downstream LLMs. | harbor up boost |
| Config Profiles | Save and manage configuration profiles for different scenarios. For example - save llama.cpp args for different models and contexts and switch between them easily. | harbor profile, Harbor App |
| Command History | Harbor keeps a local-only history of recent commands. Look up and re-run easily, standalone from the system shell history. | harbor history |
| Eject | Ready to move to your own setup? Harbor will give you a docker-compose file replicating your setup. | harbor eject |
| Harbor includes a lot more services and features. Check the Documentation links below. |
Open WebUI ⦁︎ ComfyUI ⦁︎ LibreChat ⦁︎ HuggingFace ChatUI ⦁︎ Lobe Chat ⦁︎ Hollama ⦁︎ parllama ⦁︎ BionicGPT ⦁︎ AnythingLLM ⦁︎ Chat Nio ⦁︎ mikupad
Ollama ⦁︎ llama.cpp ⦁︎ vLLM ⦁︎ TabbyAPI ⦁︎ Aphrodite Engine ⦁︎ mistral.rs ⦁︎ openedai-speech ⦁︎ Speaches ⦁︎ Parler ⦁︎ text-generation-inference ⦁︎ LMDeploy ⦁︎ AirLLM ⦁︎ SGLang ⦁︎ KTransformers ⦁︎ Nexa SDK ⦁︎ KoboldCpp
Harbor Bench ⦁︎ Harbor Boost ⦁︎ SearXNG ⦁︎ Perplexica ⦁︎ Dify ⦁︎ Plandex ⦁︎ LiteLLM ⦁︎ LangFuse ⦁︎ Open Interpreter ⦁ ︎cloudflared ⦁︎ cmdh ⦁︎ fabric ⦁︎ txtai RAG ⦁︎ TextGrad ⦁︎ Aider ⦁︎ aichat ⦁︎ omnichain ⦁︎ lm-evaluation-harness ⦁︎ JupyterLab ⦁︎ ol1 ⦁︎ OpenHands ⦁︎ LitLytics ⦁︎ Repopack ⦁︎ n8n ⦁︎ Bolt.new ⦁︎ Open WebUI Pipelines ⦁︎ Qdrant ⦁︎ K6 ⦁︎ Promptfoo ⦁︎ Webtop ⦁︎ OmniParser ⦁︎ Flowise ⦁︎ Langflow ⦁︎ OptiLLM ⦁︎ Morphic ⦁︎ SQL Chat ⦁︎ gptme ⦁︎ traefik ⦁︎ Latent Scope
See services documentation for a brief overview of each.
# Run Harbor with default services:
# Open WebUI and Ollama
harbor up
# Run Harbor with additional services
# Running SearXNG automatically enables Web RAG in Open WebUI
harbor up searxng
# Speaches includes OpenAI-compatible SST and TTS
# and connected to Open WebUI out of the box
harbor up speaches
# Run additional/alternative LLM Inference backends
# Open Webui is automatically connected to them.
harbor up llamacpp tgi litellm vllm tabbyapi aphrodite sglang ktransformers
# Run different Frontends
harbor up librechat chatui bionicgpt hollama
# Get a free quality boost with
# built-in optimizing proxy
harbor up boost
# Use FLUX in Open WebUI in one command
harbor up comfyui
# Use custom models for supported backends
harbor llamacpp model https://huggingface.co/user/repo/model.gguf
# Access service CLIs without installing them
# Caches are shared between services where possible
harbor hf scan-cache
harbor hf download google/gemma-2-2b-it
harbor ollama list
# Shortcut to HF Hub to find the models
harbor hf find gguf gemma-2
# Use HFDownloader and official HF CLI to download models
harbor hf dl -m google/gemma-2-2b-it -c 10 -s ./hf
harbor hf download google/gemma-2-2b-it
# Where possible, cache is shared between the services
harbor tgi model google/gemma-2-2b-it
harbor vllm model google/gemma-2-2b-it
harbor aphrodite model google/gemma-2-2b-it
harbor tabbyapi model google/gemma-2-2b-it-exl2
harbor mistralrs model google/gemma-2-2b-it
harbor opint model google/gemma-2-2b-it
harbor sglang model google/gemma-2-2b-it
# Convenience tools for docker setup
harbor logs llamacpp
harbor exec llamacpp ./scripts/llama-bench --help
harbor shell vllm
# Tell your shell exactly what you think about it
harbor opint
harbor aider
harbor aichat
harbor cmdh
# Use fabric to LLM-ify your linux pipes
cat ./file.md | harbor fabric --pattern extract_extraordinary_claims | grep "LK99"
# Open services from the CLI
harbor open webui
harbor open llamacpp
# Print yourself a QR to quickly open the
# service on your phone
harbor qr
# Feeling adventurous? Expose your Harbor
# to the internet
harbor tunnel
# Config management
harbor config list
harbor config set webui.host.port 8080
# Create and manage config profiles
harbor profile save l370b
harbor profile use default
# Lookup recently used harbor commands
harbor history
# Eject from Harbor into a standalone Docker Compose setup
# Will export related services and variables into a standalone file.
harbor eject searxng llamacpp > docker-compose.harbor.yml
# Run a built-in LLM benchmark with
# your own tasks
harbor bench run
# Gimmick/Fun Area
# Argument scrambling, below commands are all the same as above
# Harbor doesn't care if it's "vllm model" or "model vllm", it'll
# figure it out.
harbor model vllm
harbor vllm model
harbor config get webui.name
harbor get config webui_name
harbor tabbyapi shell
harbor shell tabbyapi
# 50% gimmick, 50% useful
# Ask harbor about itself
harbor how to ping ollama container from the webui?2024-09-29.17-22-06.mp4
In the demo, Harbor App is used to launch a default stack with Ollama and Open WebUI services. Later, SearXNG is also started, and WebUI can connect to it for the Web RAG right out of the box. After that, Harbor Boost is also started and connected to the WebUI automatically to induce more creative outputs. As a final step, Harbor config is adjusted in the App for the klmbr module in the Harbor Boost, which makes the output unparsable for the LLM (yet still undetstandable for humans).
- Installing Harbor
Guides to install Harbor CLI and App - Harbor User Guide
High-level overview of working with Harbor - Harbor App
Overview and manual for the Harbor companion application - Harbor Services
Catalog of services available in Harbor - Harbor CLI Reference
Read more about Harbor CLI commands and options. Read about supported services and the ways to configure them. - Compatibility
Known compatibility issues between the services and models as well as possible workarounds. - Harbor Bench
Documentation for the built-in LLM benchmarking service. - Harbor Boost
Documentation for the built-in LLM optimiser proxy. - Harbor Compose Setup
Read about the way Harbor uses Docker Compose to manage services. - Adding A New Service
Documentation on bringing more services into the Harbor toolkit. - Join our Discord
Get help, share your experience, and contribute to the project.
- If you're comfortable with Docker and Linux administration - you likely don't need Harbor to manage your local LLM environment. However, while growing it - you're also likely to eventually arrive to a similar solution. I know this for a fact, since that's exactly how Harbor came to be.
- Harbor is not designed as a deployment solution, but rather as a helper for the local LLM development environment. It's a good starting point for experimenting with LLMs and related services.
- Workflow/setup centralisation - you can be sure where to find a specific config or service, logs, data and configuration files.
- Convenience factor - single CLI with a lot of services and features, accessible from anywhere on your host.