在性能优化中,存在这样一种优化的手段:批处理,例如任务单独插入,每次需要和数据库交互,可以转为使用批量插入,这样可以减少数据库的交互次数,提高性能。 在 go-zero 中,executors 就是实现批处理的工具,充当任务池,做多任务缓冲。
在 executors 包下,有如下两类 executor:
- 具有特殊功能的
executor:delayexecutor:延迟函数执行LessExecutor:限定周期内只执行一次函数
- 其余三个
executor,具体包括:periodicalexecutor:定期执行批处理bulkexecutor:在periodicalexecutor的基础上,除定期执行批处理外,还支持达到给定大小的任务数执行chunkexecutor:在periodicalexecutor的基础上,除定期执行批处理外,还支持达到指定字节数执行
periodicalexecutor是bulkexecutor和chunkexecutor的基础,periodicalexecutor的使用分为三步:
- 实现 container 接口
TaskContainer:
// TaskContainer 接口定义了一个可以作为执行器的底层容器,用于周期性执行任务。
TaskContainer interface {
// AddTask 将 task 加入容器中,当返回 true 时,调用 Execute
AddTask(task any) bool
// Execute 执行 tasks
Execute(tasks any)
// RemoveAll 移除容器中的 tasks,并返回它们
RemoveAll() any
}TaskContainer接口中定义了三个方法,分别用于添加任务、执行任务和移除任务并返回。该接口中的方法最终会被periodicalexecutor所调用
type InsertTask struct {
tasks []any
execute executors.Execute
}
func newInsertTask(execute executors.Execute) *InsertTask {
return &InsertTask{
execute: execute,
}
}
// AddTask 将任务添加到容器中,并返回一个布尔值来指示是否需要在添加后刷新容器
func (i *InsertTask) AddTask(task any) bool {
i.tasks = append(i.tasks, task)
return len(i.tasks) >= 10
}
// Execute 刷新容器时处理收集的任务
func (i *InsertTask) Execute(tasks any) {
vals := tasks.([]any)
i.execute(vals)
}
// RemoveAll 移除并返回容器中的所有任务
func (i *InsertTask) RemoveAll() any {
tasks := i.tasks
i.tasks = nil
return tasks
}- 实现
Execute函数,这里只是打印
在 executors包下,Execute函数的定义是:
type Execute func(tasks []any)我们的实现只是简单打印 task 信息
execute := func(tasks []any) {
fmt.Println("执行了")
for _, task := range tasks {
fmt.Println(task)
}
}传入全部的 tasks,作为参数在 execute 中进行批处理
- 实例化
periodicalexecutor,并进行操作:
exec := executors.NewPeriodicalExecutor(time.Millisecond*100, newInsertTask(execute))
defer exec.Wait()
for i := 10; i < 20; i++ {
exec.Add(i)
}
exec.Flush()此处使用 periodicalexecutor的三个函数:
- Add:将任务添加到容器中,当返回 true 时,调用 Execute
- Flush:将任务从容器取出,执行任务
- Wait:等待容器中的任务执行完毕
此处分析 periodicalexecutor,其余两个 executor 都是依赖于这个的,本质 periodicalexecutor是一个间隔时间执行 task 的调度器,存储 task 依赖 TaskContainer的实现类;
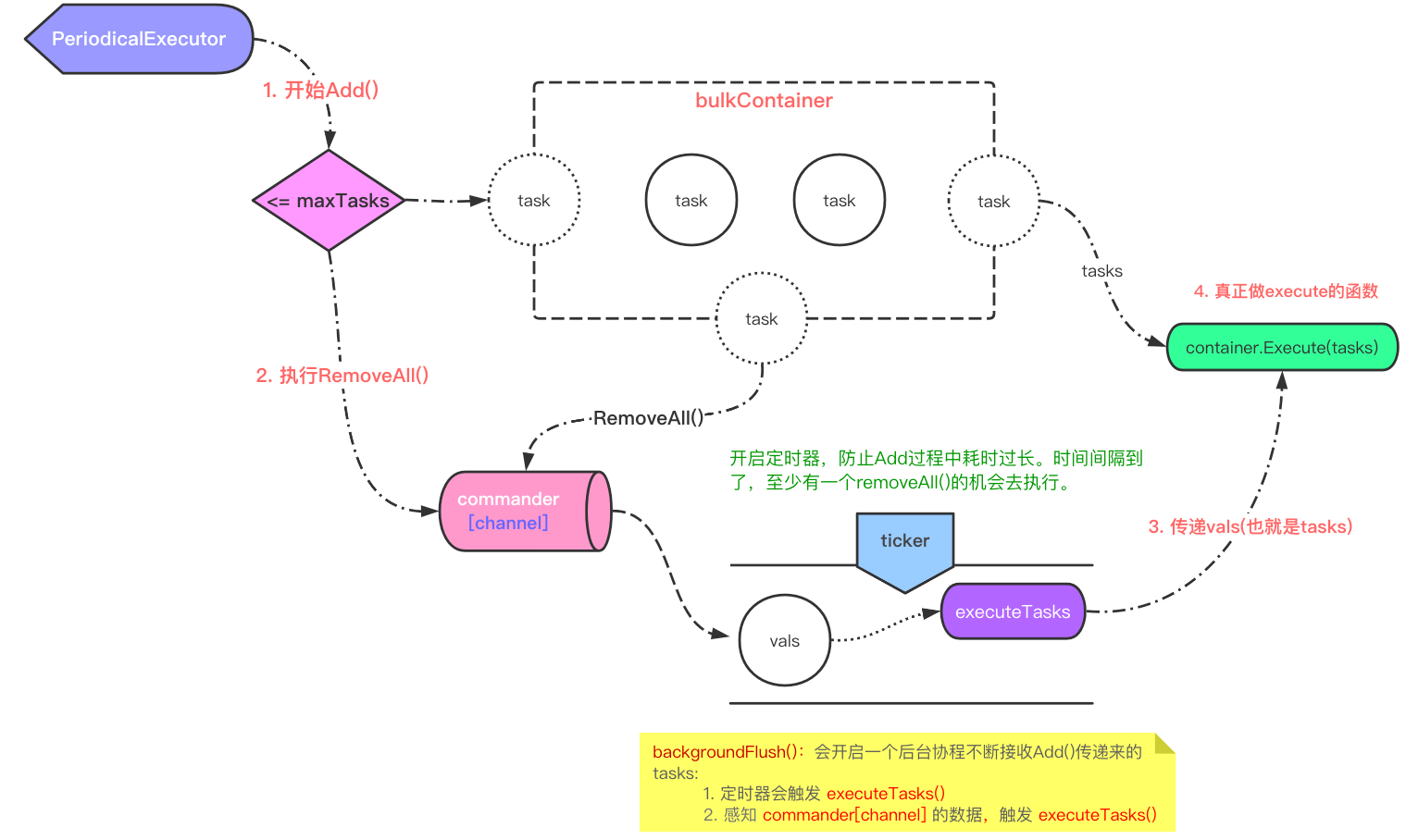
// PeriodicalExecutor 用于周期性执行任务
type PeriodicalExecutor struct {
commander chan any // 用于传递 tasks 的 chan
interval time.Duration // 周期性间隔
container TaskContainer // 执行器的容器
waitGroup sync.WaitGroup // 用于等待任务执行完成
wgBarrier syncx.Barrier // 避免 waitGroup 的竞态
confirmChan chan lang.PlaceholderType // 阻塞 Add(),避免 wg.Wait() 在 wg.Add(1) 前进行
inflight int32 // 用来判断是否可以退出当前 backgroundFlush
guarded bool // 为 false 时,允许启动 backgroundFlush
newTicker func(duration time.Duration) timex.Ticker // 时间间隔器
lock sync.Mutex
}此处先眼熟几个字段:
commander:用于传递 tasks 的 channelinterval:该时间周期取出 tasks 执行一次container:实现了TaskContainer接口的实例,用于暂存 task 的结构体newTicker:定时器,一定间隔时间,取出 tasks 执行一次
其余几个字段做线程同步,后续将详细介绍
创建实例,并设置优雅退出,退出前执行 Flush
// NewPeriodicalExecutor 间隔 interval 时间执行一次刷新
func NewPeriodicalExecutor(interval time.Duration, container TaskContainer) *PeriodicalExecutor {
executor := &PeriodicalExecutor{
// buffer 1 to let the caller go quickly
commander: make(chan any, 1),
interval: interval,
container: container,
confirmChan: make(chan lang.PlaceholderType),
newTicker: func(d time.Duration) timex.Ticker {
return timex.NewTicker(d)
},
}
// 优雅退出
proc.AddShutdownListener(func() {
executor.Flush()
})
return executor
}初始化完成后,调用 Add 将 task 添加到 executor,当 AddTask 返回 true,取出全部 tasks,写入 commander,在 backgroundFlush 中接收 tasks,并最终执行 Execute:
// Add 加入 task
func (pe *PeriodicalExecutor) Add(task any) {
if vals, ok := pe.addAndCheck(task); ok {
// vals 是从 RemoveAll 方法取出的 tasks,将全部 tasks 通过 commander 传递
// 接收是在 backgroundFlush 方法中
pe.commander <- vals
// 阻塞等待放行
<-pe.confirmChan
}
}
func (pe *PeriodicalExecutor) addAndCheck(task any) (any, bool) {
pe.lock.Lock()
defer func() {
// 允许一个协程去启动 backgroundFlush
if !pe.guarded {
// 进入后置 true,防止其他协程再次启动
pe.guarded = true
// 这里使用 defer 是为了快速执行 Unlock
// backgroundFlush 后台协程刷新 task
defer pe.backgroundFlush()
}
pe.lock.Unlock()
}()
// 实际调用的是使用方实现的 AddTask 方法
// 将 task 添加到容器中,如果返回 true,将全部 tasks 取出
if pe.container.AddTask(task) {
atomic.AddInt32(&pe.inflight, 1)
// 实际调用的是使用方实现的 RemoveAll 方法
// 移除并返回全部的 tasks
return pe.container.RemoveAll(), true
}
return nil, false
}Flush 取出此时暂存在 container中的全部 tasks,只要不为空,就作为参数传入调用 Execute:
// Flush 强制执行 task
func (pe *PeriodicalExecutor) Flush() bool {
// 本质:wg.Add(1)
pe.enterExecution()
// 匿名函数,相当于将 RemoveAll 执行结果作为参数传递
return pe.executeTasks(func() any {
pe.lock.Lock()
defer pe.lock.Unlock()
// 移除并返回全部 task
return pe.container.RemoveAll()
}())
}
func (pe *PeriodicalExecutor) executeTasks(tasks any) bool {
// 本质:wg.Done()
defer pe.doneExecution()
// 判断是否有 task
ok := pe.hasTasks(tasks)
// 只要有 task,就执行 Execute
if ok {
// 同步调用
threading.RunSafe(func() {
// 实际调用的是使用方实现的 Execute 方法
pe.container.Execute(tasks)
})
}
return ok
}执行 Add 时,退出前如果 guarded 为 false,会开启一个后台协程 backgroundFlush,该协程间隔时间取出 tasks 执行 Execute;
// 后台执行 task,同一时间仅执行一个
func (pe *PeriodicalExecutor) backgroundFlush() {
go func() {
// 返回前再次刷新,防止丢失 task
defer pe.Flush()
// 创建一个时间间隔器,用于 interval 间隔执行一次
ticker := pe.newTicker(pe.interval)
defer ticker.Stop()
// 用途:当同时满足两个 select 分支时,可能存在这样的场景:
// 1. select case 执行 commander 获取到 tasks 后,置为 true
// 2. 下次执行定时器的 case,跳过定时器中的执行
// 疑问:为什么只跳过定时器的 case,而没有跳过 commander 的 case
// 猜测:commander 的 case 中肯定是全部的 tasks,而定时器中的 case 则不一定,为了积攒更多的 tasks 一次执行,所以选择跳过
var commanded bool
// 记录最近执行时间,当 10 次间隔时间都没有新 task 产生,考虑退出该 backgroundFlush
last := timex.Now()
for {
select {
// 当 Add 返回 true,获取到全部 tasks,传入该 channel
case vals := <-pe.commander: // 从 channel 拿到 []task
commanded = true
atomic.AddInt32(&pe.inflight, -1)
// 本质:执行 wg.Add(1)
pe.enterExecution()
// 放开 Add 的阻塞,使得 Add 在 task 执行时不会被阻塞
pe.confirmChan <- lang.Placeholder
// 开始真正执行 task
pe.executeTasks(vals)
last = timex.Now()
case <-ticker.Chan(): // interval 间隔执行一次
// 置反跳过本次执行
if commanded {
commanded = false
} else if pe.Flush() { // 强制执行 task
last = timex.Now()
} else if pe.shallQuit(last) { // 定时器本轮中没有新 task,会执行到该分支
return
}
}
}
}()
}
func (pe *PeriodicalExecutor) shallQuit(last time.Duration) (stop bool) {
// 如果10次间隔时间,都没有 task,该考虑退出 backgroundFlush
if timex.Since(last) <= pe.interval*idleRound {
return
}
// checking pe.inflight and setting pe.guarded should be locked together
pe.lock.Lock()
// 确保成功执行 pe.commander <- vals
if atomic.LoadInt32(&pe.inflight) == 0 {
// 只有这里置为 false,才会开启新的 pe.backgroundFlush
pe.guarded = false
// 只有这里置为 true,才会结束该 pe.backgroundFlush
stop = true
}
pe.lock.Unlock()
return
}等待全部 task 执行完成:
// Wait 等待 task 执行完成
func (pe *PeriodicalExecutor) Wait() {
pe.Flush()
pe.wgBarrier.Guard(func() {
pe.waitGroup.Wait()
})
}这里与 Wait 相关的函数还有:
// 本质:wg.Add(1)
// 使用场景:executeTasks 前,可能是 Flush 中,也可能是 backgroundFlush 中,所以需要加单独的锁
func (pe *PeriodicalExecutor) enterExecution() {
pe.wgBarrier.Guard(func() {
pe.waitGroup.Add(1)
})
}
// 本质:wg.Done()
// 使用场景:executeTasks 执行完成后
func (pe *PeriodicalExecutor) doneExecution() {
pe.waitGroup.Done()
}所以业务方可以手动调用 Wait 保证批处理完成
该变量用于保证 wg.Add(1) 在 Wait() 之后执行
如果不使用 confirmChan,存在这样的场景:
- addAndCheck 执行完成,返回 true,
pe.commander <- vals写入成功,Add 返回 - backgroundFlush 中
vals := <-pe.commander接收 channel,但是还未执行到 wg.Add(1) - 前面 Add 返回,业务代码继续执行,可能会出现 wg.Wait() 先执行了,但是 wg.Add(1) 还未执行到的情况
如果使用 confirmChan,如何解决:
- addAndCheck 执行完成,返回 true,
pe.commander <- vals写入成功,<-pe.confirmChan阻塞等待 - backgroundFlush 值中
vals := <-pe.commander接收 channel,执行完 wg.Add(1) 后,放行pe.confirmChan <- lang.Placeholder - 此时业务代码才继续执行,保证 wg.Wait() 在 wg.Add(1) 之后执行
如果不使用 inflight,存在这样的场景:
- addAndCheck 执行结束,返回 true,但是还未执行
pe.commander <- vals - backgroundFlush 中执行 shallQuit,执行 Flush,退出
- Add 函数会阻塞在
pe.commander <- vals,导致 deadlock!
如果使用 inflight,如何解决:
- 当 addAndCheck 执行结束,返回 true,但是还未执行
pe.commander <- vals,此时inflight为 1 - backgroundFlush 中执行 shallQuit,由于
inflight为1,stop 为 false,不会退出 vals := <-pe.commander中获取到vals后再将inflight设置为 0
使用该值判断是否能执行 backgroundFlush
- addAndCheck 中加锁 + guarded 判断和 guarded 置 true 保证 backgroundFlush 只运行一次
- 超时时间,结合 inflight 和 guarded 置 false,保证下次 backgroundFlush 还能启动
考虑:为什么不把 addAndCheck 中判断 guarded 放入 backgroundFlush 呢,感觉内聚性更好
使用该值来避免多次执行 Flush
如果不存在 commanded,存在这样的场景:
vals := <-pe.commandercase 执行- 紧接着
<-ticker.Chan()case 执行,但是可能此时 task 只有很少
引入该值后,可以避免该场景,一次可以积攒更多的 task 集中执行
尝试自己解答一波
TaskContainer接口中,获取 tasks(RemoveAll) 和 执行 task(Execute)为什么要分开?
如果不使用 channel 解耦,分开两个接口,会存在这样的问题:执行 tasks 时,如果由 executor保证线程安全,会导致执行 tasks 时阻塞 Add(),如果由 container自己保证线程安全,会提高实现的难度
- 为什么
backgroundFlush要超时退出?
当一段间隔时间(10次)内都没有新任务添加,且当前没有任务正在执行,可以考虑退出后台任务循环,以防止无谓的空闲循环占用资源,当有任务再添加时,重新启动该后台协程
https://www.bookstack.cn/read/go-zero-1.3-zh/executors.md https://draveness.me/golang/docs/part2-foundation/ch05-keyword/golang-select/