首先介绍一下,什么是哈希算法。Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。(来源:百度百科) 对于集群,通常采用哈希取模算法作为路由策略。
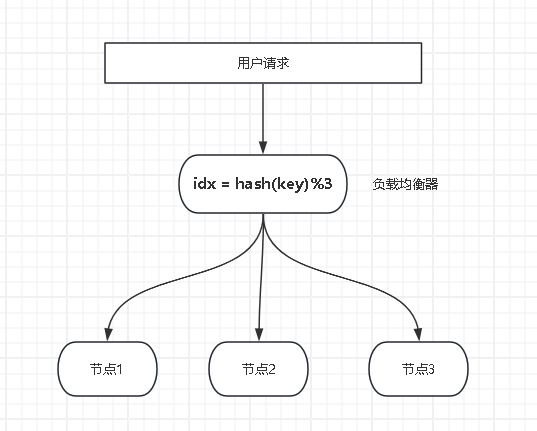
然而在有状态服务集群中(例如分布式缓存服务),当服务节点的增加或删除,会导致原有服务状态映射全部失效,需要改进负载均衡算法。
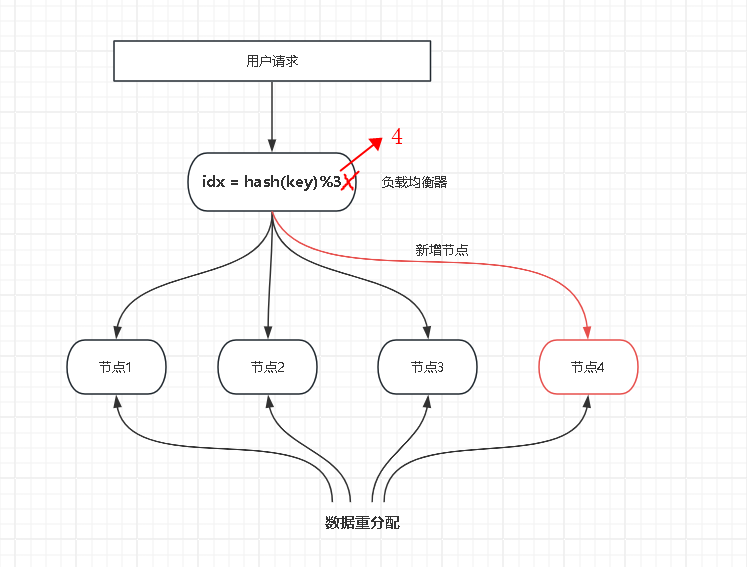
基于上面的缺点,提出一种新的算法:一致性哈希。一致性哈希可以实现服务节点的增加或删除,只影响一小部分数据的映射关系,可以有效降低有状态服务集群扩缩容流程的数据迁移成本。
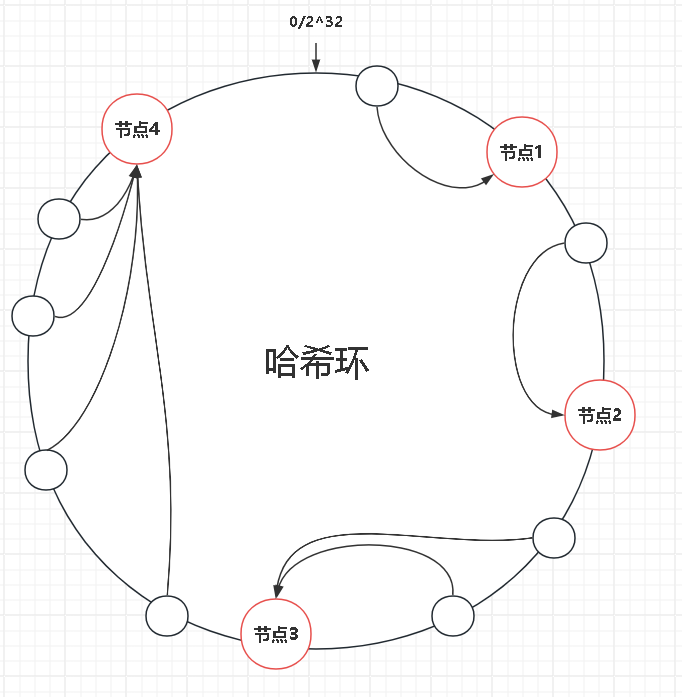
在一致性哈希算法中,数据被映射到一个连续的哈希环上,这个环的数值范围通常在 0~232-1 间。 节点也被散列到相同的环上。数据通过一定的哈希函数映射到环上的一点,然后沿着顺时针寻找最近的节点,将数据分配给该节点。
当新增节点5,流程如下:
- 计算节点5在哈希环上的位置,例如在节点 3-4 之间
- 找到节点5沿顺时针向下的下一个节点4
- 找到节点3-5间的全部数据,从原本所属节点4,迁移到节点5中
- 节点5添加入环
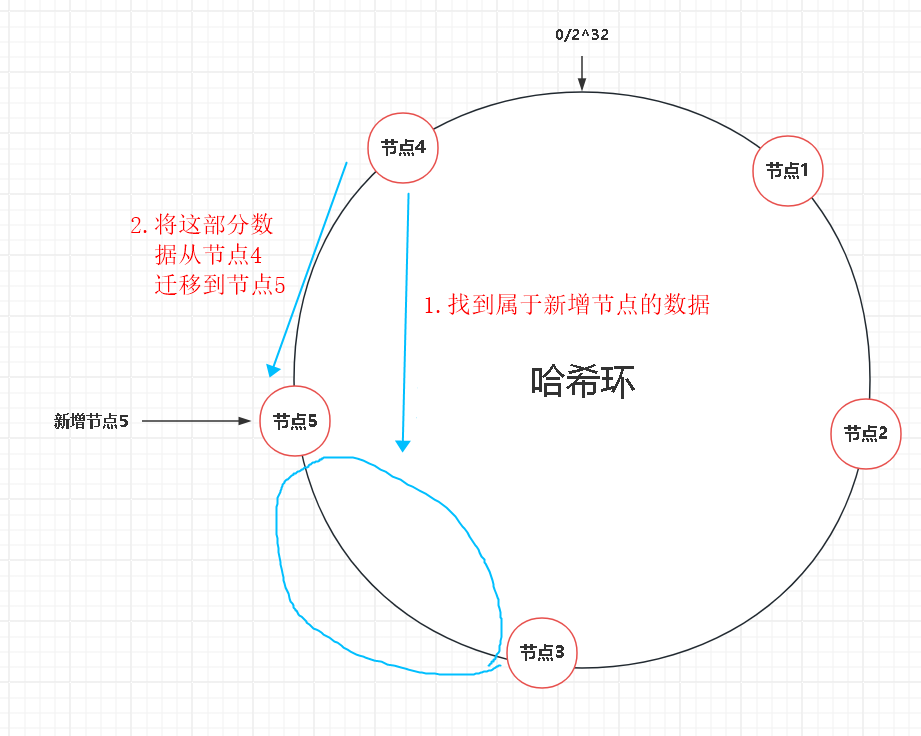
可以看到,新增节点,只会影响新增节点沿顺时针下一个节点,其他节点数据完全不影响
当删除节点3,流程如下:
- 找到节点3沿顺时针向下的下一个节点4
- 将节点3的全部数据迁移到节点4上
- 从哈希环中移除节点3
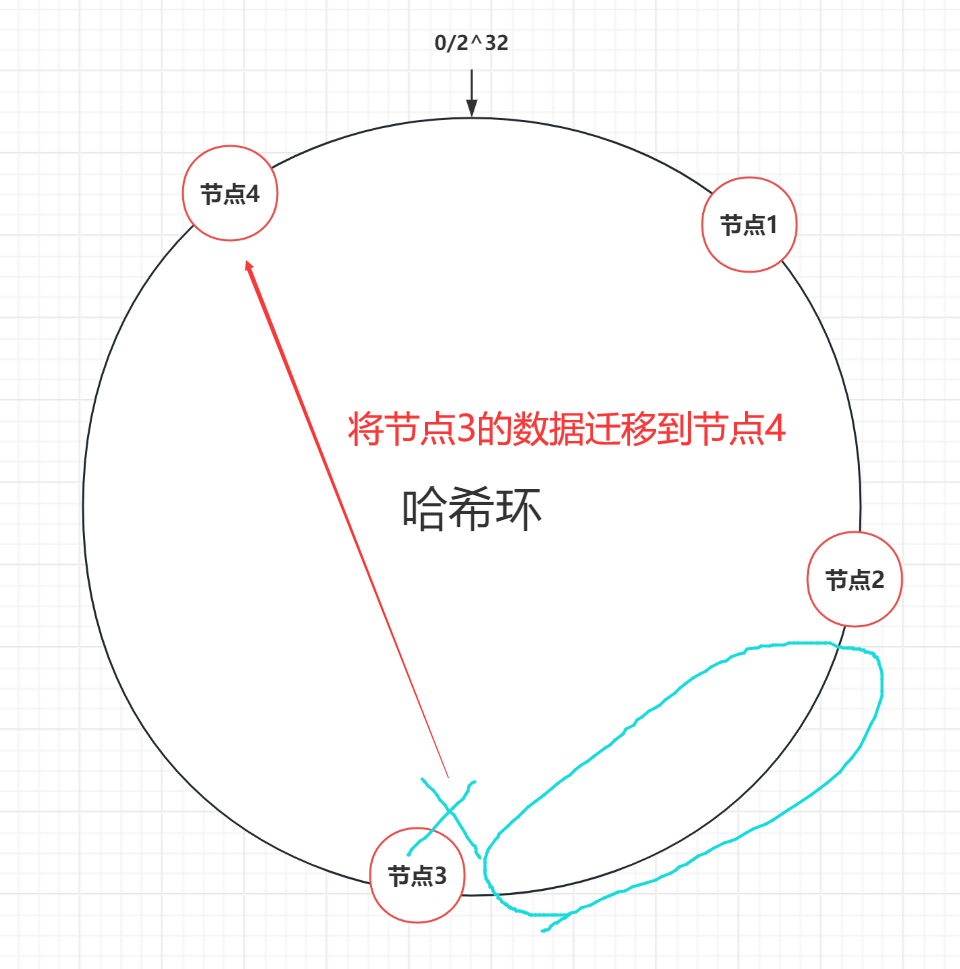
可以看到,节点删除,只会影响删除节点沿顺时针的下一个节点,其他节点数据完全不影响
最基本的一致性哈希算法直接应用于负载均衡系统,效果仍然是不理想的,可能存在以下两个问题
- 数据倾斜。如果节点的数量很少,而哈希环的空间很大,大部分情况下,节点在环上的位置会很不均匀,挤在某个很小的区域,最终对分布式缓存造成的影响就是,不同节点存储的数据量差异极大,造成严重的数据倾斜。
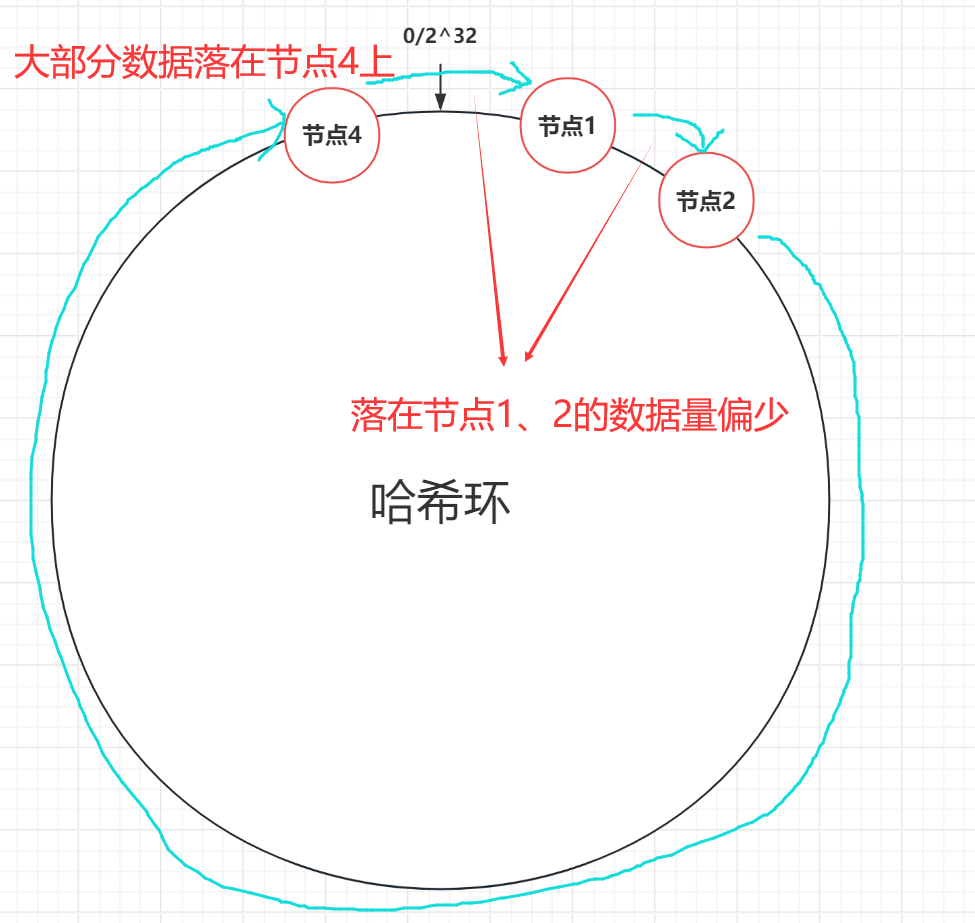
- 服务雪崩。例如,当节点1删除,节点1的全部数据将落在节点2上,造成节点2的压力瞬间增大,可能直接打垮节点2,节点2下线,节点1、节点2的全部数据又将打到节点3上,最终服务压力就像滚雪球一样累积给剩余节点,最终造成服务雪崩。
为了解决以上两个问题,最好的解决方案就是扩展整个环上的节点数量,因此我们引入了虚拟节点的概念。一个真实节点可以映射多个虚拟节点,再将虚拟节点映射到哈希环上,实际访问时,通过映射从虚拟节点可以找到真实节点。
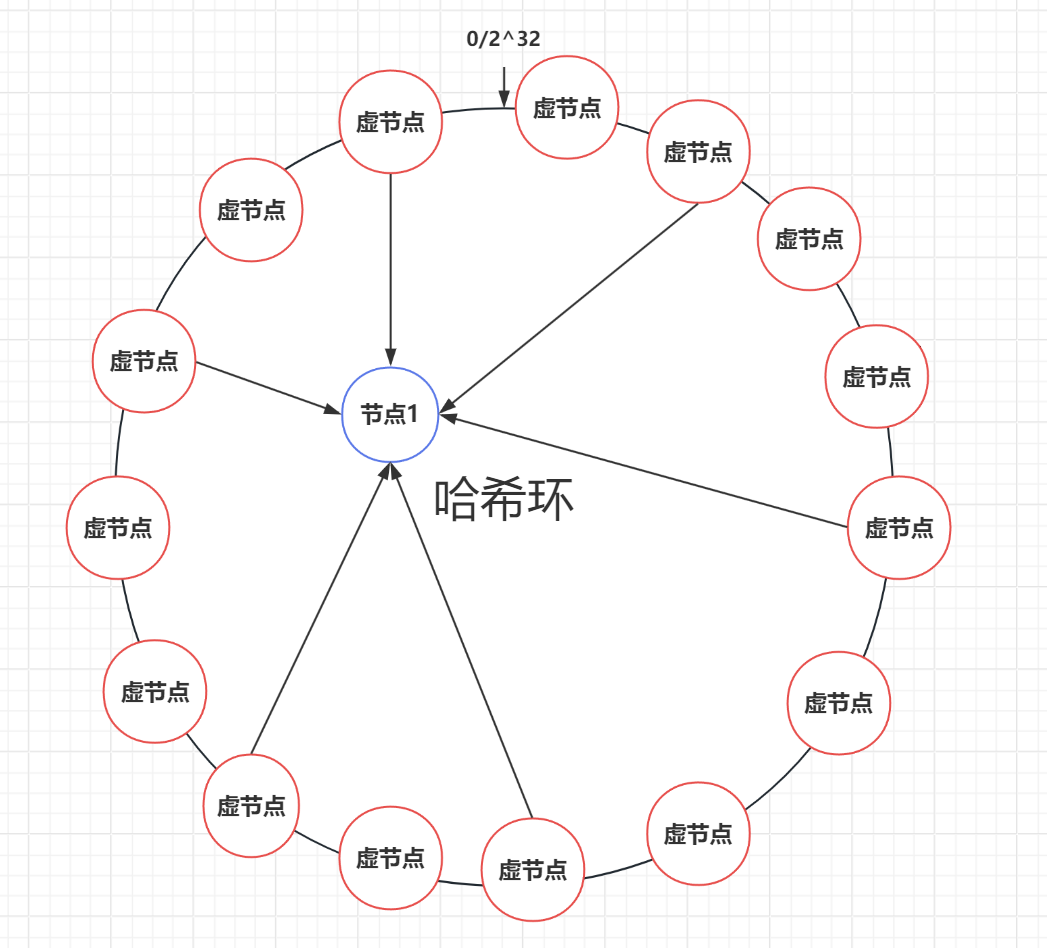
引入虚拟节点,当一个真实节点下线后,会同时从哈希环上撤走其映射的多个虚节点,这样数据的压力就可以均匀地分摊到多个不同的真实节点上。
使用 go-zero 的一致性哈希,测试添加节点和删除节点时,节点的压力分布情况
func main() {
fmt.Println("添加节点测试")
addTest()
fmt.Println("=========================================")
fmt.Println("删除节点测试")
removeTest()
}
// 添加节点测试
func addTest() {
reqNum := 100000
// 创建环
dispatcher := hash.NewConsistentHash()
nodes := []string{"localhost:8080", "localhost:8081", "localhost:8082", "localhost:8083", "localhost:8084"}
// 添加真实节点
for _, node := range nodes {
dispatcher.Add(node)
}
batchGet(reqNum, dispatcher)
addNode := "localhost:9090"
fmt.Println("添加真实节点:", addNode)
// 添加真实节点
dispatcher.Add(addNode)
batchGet(reqNum, dispatcher)
}
// 移除节点测试
func removeTest() {
reqNum := 100000
// 创建环
dispatcher := hash.NewConsistentHash()
nodes := []string{"localhost:8080", "localhost:8081", "localhost:8082", "localhost:8083", "localhost:8084"}
// 添加真实节点
for _, node := range nodes {
dispatcher.Add(node)
}
batchGet(reqNum, dispatcher)
fmt.Println("移除真实节点:", nodes[0])
// 移除真实节点
dispatcher.Remove(nodes[0])
batchGet(reqNum, dispatcher)
}
func batchGet(reqNum int, dispatcher *hash.ConsistentHash) {
nodeCount := make(map[string]int64)
// 尝试请求 10w 次
for i := 0; i < reqNum; i++ {
node, ok := dispatcher.Get(rand.Int())
if ok {
nodeCount[node.(string)]++
}
}
for node, count := range nodeCount {
fmt.Printf("group %s:%d(%.02f%%)\n", node, count, float64(count)/float64(reqNum)*100)
}
}执行得到结果:
添加节点测试
group localhost:8084:21143(21.14%)
group localhost:8081:20133(20.13%)
group localhost:8083:20795(20.79%)
group localhost:8080:19225(19.23%)
group localhost:8082:18704(18.70%)
添加真实节点: localhost:9090
group localhost:8084:18052(18.05%)
group localhost:8081:16085(16.09%)
group localhost:8080:14832(14.83%)
group localhost:8083:17432(17.43%)
group localhost:8082:16012(16.01%)
group localhost:9090:17587(17.59%)
=========================================
删除节点测试
group localhost:8081:20369(20.37%)
group localhost:8083:20863(20.86%)
group localhost:8084:21178(21.18%)
group localhost:8082:18749(18.75%)
group localhost:8080:18841(18.84%)
移除真实节点: localhost:8080
group localhost:8081:24529(24.53%)
group localhost:8084:27167(27.17%)
group localhost:8082:22762(22.76%)
group localhost:8083:25542(25.54%)
可以观察到,执行 10w 次请求,各个节点承担压力相对均匀。当添加节点时,各个节点都减少了压力。当删除节点时,压力较均匀地分摊到全部节点。
基于前面的原理分析,可以提炼出go-zero中一致性哈希的核心接口:
- 添加节点
- 删除节点
- 查询节点
type (
// Func 定义hash函数
Func func(data []byte) uint64
// ConsistentHash 一致性哈希实现
ConsistentHash struct {
// hash函数
hashFunc Func
// 添加一个真实节点,对应创建的最大虚拟节点个数
replicas int
// 虚拟节点列表
keys []uint64
// 虚拟节点到真实节点的映射,当存在冲突,多个真实节点追加到相同的 key
ring map[uint64][]any
// 真实节点的map,用于快速判断是否存在
nodes map[string]lang.PlaceholderType
// 读写锁
lock sync.RWMutex
}
)go-zero 中使用切片存储一致性哈希环,由于应用于负载均衡场景,只存了节点,没有存数据。 三个最核心的数据结构,分别是:
- nodes:存储真实节点
- ring:存储虚拟节点到真实节点的映射
- keys:存储虚拟节点的列表
go-zero 中存在两个初始化函数。
NewConsistentHash也是使用默认参数调用NewCustomConsistentHash
const (
minReplicas = 100 // 添加真实节点时,虚拟节点最大个数
)
func Hash(data []byte) uint64 {
return murmur3.Sum64(data)
}
// NewConsistentHash 创建默认hash环实例
func NewConsistentHash() *ConsistentHash {
return NewCustomConsistentHash(minReplicas, Hash)
}
// NewCustomConsistentHash 自定义参数的一致性哈希实例
func NewCustomConsistentHash(replicas int, fn Func) *ConsistentHash {
// 使用默认虚拟节点个数,至少 100 个
if replicas < minReplicas {
replicas = minReplicas
}
// 使用默认哈希函数
if fn == nil {
fn = Hash
}
return &ConsistentHash{
hashFunc: fn,
replicas: replicas,
ring: make(map[uint64][]any),
nodes: make(map[string]lang.PlaceholderType),
}
}const (
prime = 16777619
)
// 在遇到哈希冲突时需要重新对key进行哈希计算
// 为了减少冲突的概率前面追加了一个质数 prime来减小冲突的概率
func innerRepr(node any) string {
return fmt.Sprintf("%d:%v", prime, node)
}
// 返回 node 的序列化表示
func repr(node any) string {
return lang.Repr(node)
}- repr 函数获取 node 的序列化表示,作为 node 的标识
- innerRepr 函数获取 16777619:node 的序列化表示,也是作为 node 的标识,不过是在遇到hash冲突时调用,添加一个质数,减少冲突的概率
go-zero 中的添加方法有三个,本质都是调用 AddWithReplicas
// Add 添加真实节点
func (h *ConsistentHash) Add(node any) {
h.AddWithReplicas(node, h.replicas)
}
// AddWithWeight 按百分比权重添加节点,权重越高,虚拟节点个数越多
func (h *ConsistentHash) AddWithWeight(node any, weight int) {
// 最多添加h.replicas个的虚拟节点
replicas := h.replicas * weight / TopWeight
h.AddWithReplicas(node, replicas)
}
// AddWithReplicas 添加真实节点
func (h *ConsistentHash) AddWithReplicas(node any, replicas int) {
// 支持重复添加
// 先删除该真实节点
h.Remove(node)
// 每次添加真实节点,对应的虚拟节点个数不能超过该值
if replicas > h.replicas {
replicas = h.replicas
}
// 计算真实节点的key
nodeRepr := repr(node)
h.lock.Lock()
defer h.lock.Unlock()
// 将真实节点添加到nodes map中
h.addNode(nodeRepr)
for i := 0; i < replicas; i++ {
// 计算虚拟节点的hash值
hash := h.hashFunc([]byte(nodeRepr + strconv.Itoa(i)))
// 添加虚拟节点
h.keys = append(h.keys, hash)
// 建立虚拟节点 -> 真实节点
// 可能出现哈希冲突,使用链表法解决,追加到相同的切片中
h.ring[hash] = append(h.ring[hash], node)
}
// 对虚拟节点hash值排序,方便快速找到虚拟节点
sort.Slice(h.keys, func(i, j int) bool {
return h.keys[i] < h.keys[j]
})
}总结,添加真实节点本质是干了四件事:
- 添加真实节点
- 添加虚拟节点
- 添加虚拟节点到真实节点的映射,可能出现hash冲突,go-zero中使用链表法解决,直接追加到同一个切片中
- 前面提到,go-zero 中使用切片存储一致性哈希环,所以添加虚拟节点后,还要对该虚拟节点的切片进行排序,方便使用二分法快速查找虚拟节点
// Remove 删除真实节点
func (h *ConsistentHash) Remove(node any) {
// 返回node的字符串表示
nodeRepr := repr(node)
h.lock.Lock()
defer h.lock.Unlock()
// 真实节点不存在,直接返回
if !h.containsNode(nodeRepr) {
return
}
// 移除真实节点对应的虚拟节点
for i := 0; i < h.replicas; i++ {
// 计算虚拟节点的哈希值
hash := h.hashFunc([]byte(nodeRepr + strconv.Itoa(i)))
// 根据哈希值找到该虚拟节点的下标
index := sort.Search(len(h.keys), func(i int) bool { return h.keys[i] >= hash })
// 二次校验确实是这个虚拟节点,在虚拟节点切片上删除该虚拟节点
if index < len(h.keys) && h.keys[index] == hash {
// 使用index之后的元素(index+1)前移一位,覆盖index位置的元素
h.keys = append(h.keys[:index], h.keys[index+1:]...)
}
// 删除虚拟节点到真实节点的映射
h.removeRingNode(hash, nodeRepr)
}
// 删除真实节点
h.removeNode(nodeRepr)
}
// 删除虚拟节点 -> 真实节点的映射关系
func (h *ConsistentHash) removeRingNode(hash uint64, nodeRepr string) {
// 校验虚拟节点是否在哈希环中
if nodes, ok := h.ring[hash]; ok {
// 新建空的切片,保持原容量,等同于:make([]any, 0, len(nodes))
newNodes := nodes[:0]
// 遍历虚拟节点对应的真实节点列表,重新把非当前的真实节点加入到映射
for _, x := range nodes {
if repr(x) != nodeRepr {
newNodes = append(newNodes, x)
}
}
// 如果虚拟节点还有对应的其他真实节点,使用新真实节点列表作为映射的 value
if len(newNodes) > 0 {
h.ring[hash] = newNodes
} else { // 否则直接删掉整个映射
delete(h.ring, hash)
}
}
}总结,删除真实节点本质上做了三件事:
- 删除虚拟节点
- 删除虚拟节点到真实节点的映射
- 删除真实节点
// Get 根据给定的 v 返回对应的节点
func (h *ConsistentHash) Get(v any) (any, bool) {
h.lock.RLock()
defer h.lock.RUnlock()
// 哈希环为空,返回 nil
if len(h.ring) == 0 {
return nil, false
}
// 针对 v 计算得到 hash 值
hash := h.hashFunc([]byte(repr(v)))
// 二分法返回第一个大于等于hash值的索引(相当于沿顺时针方向,找到第一个大于等于hash值的虚拟节点)
index := sort.Search(len(h.keys), func(i int) bool {
return h.keys[i] >= hash
}) % len(h.keys)
// index 虚拟节点的索引
// h.keys[index] 找到对应虚拟节点的值
// h.ring[h.keys[index]] 找到虚拟节点对应的真实节点切片
nodes := h.ring[h.keys[index]]
switch len(nodes) {
case 0: // 如果虚拟节点没有对应的真实节点,返回空值
return nil, false
case 1: // 如果虚拟节点只有一个对应的真实节点,返回该真实节点
return nodes[0], true
default: // 如果虚拟节点有多个对应的真实节点,使用innerRepr(v)计算得到hash值,再使用该值在虚拟节点对应的切片中找到对应的节点
innerIndex := h.hashFunc([]byte(innerRepr(v)))
pos := int(innerIndex % uint64(len(nodes)))
return nodes[pos], true
}
}前面添加真实节点时,将虚拟节点列表进行了排序。在查找节点时,可以直接使用二分法,快速找到 v 对应的虚拟节点。
同时,在添加真实节点时,会建立虚拟节点到真实节点的映射,此时可以反过来找到真实节点,建立映射时可能存在hash冲突,会对应多个真实节点,此时使用innerRepr求hash函数,取其中一个真实节点返回。
优点:
- 实现简单,使用切片存储节点,仅需要维护好虚拟节点、真实节点及关联关系即可
缺点:
- 一致性哈希环的存储结构使用切片,过于简单,效率很低,可以替换成效率更高的存储结构,例如红黑树、跳表等,使用切片:
- 添加节点时进行排序,时间复杂度
O(nLogn) - 删除节点时查找删除,时间复杂度
O(nLogn) - 查找时时间复杂度为
O(Logn)
- 添加节点时进行排序,时间复杂度
- 存储在内存中,集群中的每个服务都需要在本地存储一份全部节点数据,可以将这部分数据存储到 Redis 上集群服务共用
总结:虽然go-zero中的一致性哈希实现很简陋,但是对于它本身的应用场景来说,已经足够
go-zero 中将一致性哈希算法的核心逻辑和数据的存储放在同一个结构体中,我们自己实现可以将逻辑和数据存储分离开。
核心类就一个,负责哈希算法的逻辑部分:
const (
minReplicas = 100
)
type (
HashFunc func(data []byte) uint64
// ConsistentHash 一致性哈希实现
ConsistentHash struct {
hashRing HashRing // 哈希环
hashFunc HashFunc // 哈希函数
replicas int // 添加真实节点时,结合权重,添加对应数量的虚拟节点
}
)
func NewConsistentHash() *ConsistentHash {
return NewCustomConsistentHash(local.NewSliceHashRing(), Hash, minReplicas)
}
// NewCustomConsistentHash 使用默认参数创建一致性哈希实例
func NewCustomConsistentHash(hashRing HashRing, hashFunc HashFunc, replicas int) *ConsistentHash {
if hashRing == nil {
hashRing = local.NewSliceHashRing() // 使用默认的hashRing
}
if hashFunc == nil {
hashFunc = Hash
}
if replicas < minReplicas {
replicas = minReplicas
}
return &ConsistentHash{
hashRing: hashRing,
hashFunc: hashFunc,
replicas: replicas,
}
}
func Hash(data []byte) uint64 {
return murmur3.Sum64(data)
}其中:
- hashRing:哈希环是数据存储的接口类型
- hashFunc:哈希函数
- replicas:一个真实节点对应的虚拟节点个数
哈希环是一个抽象接口,定义了逻辑和数据交互的方法:
// HashRing 哈希环接口
type HashRing interface {
Lock() error // 加锁
Unlock() error // 解锁
AddNode(node string, virtualNode uint64, idx int) error // 添加节点
RemoveNode(node string, virtualNode uint64, idx int) error // 删除节点
ContainsNode(node string) bool // 检查节点是否存在
GetNode(hash uint64) (string, bool) // 根据hash获取节点
}从一致性哈希算法的逻辑来看,添加节点做的事很简单:
- 如果节点存在,就删除
- 添加真实节点和对应的虚拟节点,具体怎么存,看哈希环的实现
// Add 添加真实节点
func (h *ConsistentHash) Add(node string) {
// 支持重复添加
// 先删除该真实节点
h.Remove(node)
// 加锁
h.hashRing.Lock()
defer h.hashRing.Unlock()
for i := 0; i < h.replicas; i++ {
// 计算虚拟节点的哈希值
virtualNode := h.hashFunc([]byte(node + strconv.Itoa(i)))
// 添加节点
err := h.hashRing.AddNode(node, virtualNode, i)
if err != nil {
panic(err)
}
}
}删除节点做的也很简单:
- 检查节点是否存在,fast path
- 删除真实节点和对应的虚拟节点
// Remove 删除真实节点
func (h *ConsistentHash) Remove(node string) {
// 加锁
h.hashRing.Lock()
defer h.hashRing.Unlock()
// 检查节点是否存在哈希环中,不存在直接返回
if !h.hashRing.ContainsNode(node) {
return
}
for i := 0; i < h.replicas; i++ {
// 计算虚拟节点的哈希值
virtualNode := h.hashFunc([]byte(node + strconv.Itoa(i)))
// 删除节点
err := h.hashRing.RemoveNode(node, virtualNode, i)
if err != nil {
panic(err)
}
}
}计算出查询节点的哈希值,交给哈希环的实现查询:
// Get 查询节点,最终返回具体的真实节点
func (h *ConsistentHash) Get(key string) (string, bool) {
// 加锁
h.hashRing.Lock()
defer h.hashRing.Unlock()
// 计算key的哈希值
hash := h.hashFunc([]byte(key))
// 获取对应的真实节点
return h.hashRing.GetNode(hash)
}单机版哈希环依然使用slice存储哈希环,只是单独将哈希环数据存储部分抽成接口。 最核心的数据结构依然是:
- 存储虚拟节点的切片
- 存储虚拟节点到真实节点映射的map
- 存储真实节点的map
考虑几个工程实现问题:
- 如何存储虚拟节点?
使用切片
- 如何存储虚拟节点和真实节点的关系?
使用 map,以虚拟节点做 key,真实节点做 value,当发生冲突,追加到同一个 key 下。
- 虚拟节点如何生成?
使用固定 replicas 值,一个真实节点映射 replicas 个虚拟节点
- 顺时针查询第一个虚拟节点如何实现?
添加虚拟节点时,让存储的slice保持有序,查询时使用二分法找到第一个大于等于查询hash值,且以虚拟节点长度取余,确保在虚拟节点范围内形成环
- 同一个虚拟节点,对应多个真实节点,返回哪个真实节点?
go-zero 中是再hash,取余真实节点数量,结果值作为下标索引返回;这里使用随机下标值返回
package local
import (
"math/rand"
"sort"
"sync"
)
// SliceHashRing 使用Slice实现HashRing接口
type SliceHashRing struct {
keys []uint64 // 虚拟节点列表
ring map[uint64][]string // 虚拟节点到真实节点的映射
nodes map[string]struct{} // 真实节点map
lock sync.RWMutex
}
func NewSliceHashRing() *SliceHashRing {
return &SliceHashRing{
keys: make([]uint64, 0),
ring: make(map[uint64][]string),
nodes: make(map[string]struct{}),
}
}
// Lock 加锁
func (s *SliceHashRing) Lock() error {
s.lock.Lock()
return nil
}
// Unlock 解锁
func (s *SliceHashRing) Unlock() error {
s.lock.Unlock()
return nil
}
// AddNode 添加真实节点、虚拟节点,建立虚拟节点到真实节点的映射
func (s *SliceHashRing) AddNode(node string, virtualNode uint64, _ int) error {
// 添加真实节点
s.nodes[node] = struct{}{}
// 添加虚拟节点
s.keys = append(s.keys, virtualNode)
// 建立虚拟节点到真实节点的映射,当出现hash冲突,追加到切片中
s.ring[virtualNode] = append(s.ring[virtualNode], node)
// 为了保持有序性,每次添加虚拟节点都需要排序
sort.Slice(s.keys, func(i, j int) bool { return s.keys[i] < s.keys[j] })
return nil
}
// RemoveNode 删除真实节点、虚拟节点,删除虚拟节点到真实节点的映射
func (s *SliceHashRing) RemoveNode(node string, virtualNode uint64, _ int) error {
// 删除真实节点
delete(s.nodes, node)
// 从存储虚拟节点的环上,找到虚拟节点
idx := sort.Search(len(s.keys), func(i int) bool { return s.keys[i] >= virtualNode })
// 删除该虚拟节点
if idx < len(s.keys) && s.keys[idx] == virtualNode {
// 使用idx后的元素,前移一位,覆盖掉s.key[idx]
s.keys = append(s.keys[:idx], s.keys[idx+1:]...)
}
// 删除虚拟节点到真实节点的映射
// 找到虚拟节点对应的真实节点列表
if nodes, ok := s.ring[virtualNode]; ok {
// 从真实节点列表中踢出该真实节点
newNodes := make([]string, 0, len(nodes))
for _, x := range nodes {
if x != node {
newNodes = append(newNodes, x)
}
}
if len(newNodes) > 0 {
s.ring[virtualNode] = newNodes
} else {
delete(s.ring, virtualNode)
}
}
// 由于添加时节点有序,删除是用前移覆盖的方式删除的,不需要再排序
return nil
}
// ContainsNode 判断真实节点是否存在
func (s *SliceHashRing) ContainsNode(node string) bool {
_, ok := s.nodes[node]
return ok
}
// GetNode 根据虚拟节点获取真实节点
func (s *SliceHashRing) GetNode(hash uint64) (string, bool) {
// 哈希环为空,返回 nil
if len(s.keys) == 0 {
return "", false
}
// 找到第一个大于等于hash的虚拟节点(相当于顺时针)
idx := sort.Search(len(s.keys), func(i int) bool { return s.keys[i] >= hash }) % len(s.keys)
// 获取对应的真实节点列表 s.keys[idx]:虚拟节点
nodes, ok := s.ring[s.keys[idx]]
if !ok || len(nodes) == 0 {
return "", false
}
if len(nodes) == 1 {
return nodes[0], true
}
// 从列表中随机取出一个真实节点返回
return nodes[rand.Intn(len(nodes))], true
}为了方便检索,使用 redis 中的 zset 存储哈希环,zset 是一个可排序的 set。zset 中每个元素需要指定 score 值和 member 值,zset 中的元素可以根据 score 进行排序,其底层存储为跳表,插入、删除和查询时间复杂度都为O(logN)。
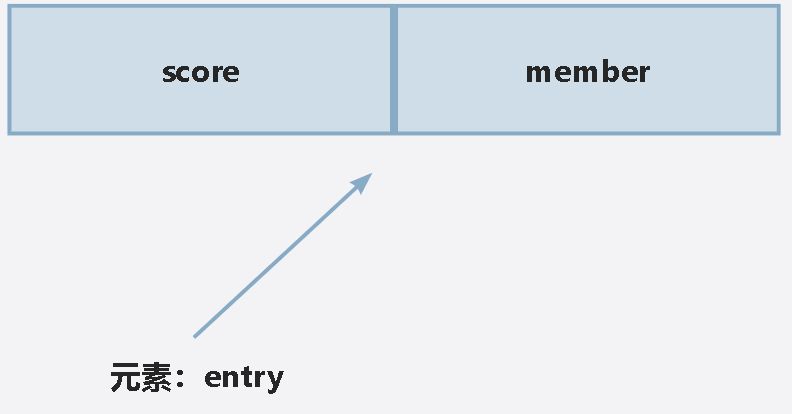
- 添加节点:zadd,添加一个或多个 member 及其 score 到 zset 中
- 删除节点:zremrangebyscore,删除指定 score 范围内的全部元素
- 查找节点:zrange+
byscore参数,返回指定 score 范围内的全部元素 - 节点是否存在:zscore,返回指定 member 对应的 score。
一致性哈希表中相关操作:
- 添加节点:虚拟节点的哈希值作为 score,真实节点作为 member,zadd 能满足
- 删除节点:根据 socre 可以删除整个元素,zremrangebyscore 能满足
- 查找节点:通过传入值查找真实节点(通过hash,查找第一个大于等于hash的score),可以设置检索边界为 [hash,+∞),同时将 limit 设置为 1,代表只返回第一个元素;如果查不到,需要反向查询 [-∞,hash] 的第一个元素,达成环的效果。
- 判断节点是否存在:通过 zscore 查找真实节点,检查其对应的 score 是否存在,来判断是否存在节点
一些注意项:
- zset 中,如果使用同一个真实节点作为 member,最多只能设置一个虚拟节点,可以通过为真实节点添加后缀来标识同一个真实节点,但是实际底层作为 member 存储不同值
- zset 中,set 表示的是 member 不同,并不代表 score 不可以相同,所以当 score 相同(发生了哈希冲突)时,member 需要存储的是真实节点的列表。
// getRawNodeKey 为真实节点node添加后缀,区分不同节点
func (z *ZSetHashRing) getRawNodeKey(node string, idx int) string {
return fmt.Sprintf("%s-%d", node, idx)
}
// getRawNode 根据真实节点key获取真实节点node
func (z *ZSetHashRing) getRawNode(rawNodeKey string) string {
idx := strings.LastIndex(rawNodeKey, "-")
return rawNodeKey[:idx]
}使用 zset 添加节点会比较复杂,主要原因是需要处理哈希冲突的场景:
- 查询 score 位置是否存在 member
- 如果已存在 member,需要将当前真实节点追加到 member 中,并删除当前节点
- 将节点添加到 member 列表,zadd 加入到 zset 中
// AddNode 添加节点
// 相同 score 可能存在多个节点(发生hash冲突),如果冲突了需要合并放到一个元素中
func (z *ZSetHashRing) AddNode(node string, virtualNode uint64, idx int) error {
score := strconv.FormatUint(virtualNode, 10)
rawNodeKey := z.getRawNodeKey(node, idx)
// 查询score位置是否存在member
entities, err := z.client.ZRangeByScore(context.Background(), z.key, &redis.ZRangeBy{Min: score, Max: score}).Result()
if err != nil && !errors.Is(err, redis.Nil) {
return fmt.Errorf("redis hash add fail, err:%w", err)
}
if len(entities) > 1 {
return fmt.Errorf("invalid score entity len: %d", len(entities))
}
var members []string
// 存在冲突,把已经存在的节点删掉
if len(entities) == 1 {
// 先反序列化为切片
members = z.UnmarshalEntries(entities)
// 已有该节点,返回
for _, member := range members {
if member == rawNodeKey {
return nil
}
}
// 删除当前节点
err = z.client.ZRemRangeByScore(context.Background(), z.key, score, score).Err()
if err != nil {
return fmt.Errorf("redis ring add fail, err: %w", err)
}
}
// 追加最新节点
members = append(members, rawNodeKey)
entitiesBytes := z.MarshalEntries(members)
return z.client.ZAdd(context.Background(), z.key, &redis.Z{Score: float64(virtualNode), Member: entitiesBytes}).Err()
}由于相同 score 可能哈希冲突,当删除的 member 中存在多个真实节点列表,只需要删除其中一个:
- 查询 score 位置是否存在 member
- 从返回的 member 中找到并删除此次要删除的真实节点,并从 zset 中删除整个节点
- 如果删除该真实节点后,member 中真实节点列表已经空了,那就直接返回
- 如果删除该真实节点后,member 中真实节点还有剩余值,还需要再加入到 zset 中
// RemoveNode 删除节点
// 相同 score 可能存在多个节点,此时需要先找到要删除的节点,再进行删除其中一个
func (z *ZSetHashRing) RemoveNode(node string, virtualNode uint64, idx int) error {
score := strconv.FormatUint(virtualNode, 10)
rawNodeKey := z.getRawNodeKey(node, idx)
// 查询score位置是否存在member(寻找虚拟节点)
entities, err := z.client.ZRangeByScore(context.Background(), z.key, &redis.ZRangeBy{Min: score, Max: score}).Result()
// 没找到也算error
if err != nil {
return fmt.Errorf("redis hash remove fail, err:%w", err)
}
if len(entities) > 1 {
return fmt.Errorf("invalid score entity len: %d", len(entities))
}
members := z.UnmarshalEntries(entities)
// 判断虚拟节点中是否存在对应的真实节点
index := -1
for i, member := range members {
if member == rawNodeKey {
index = i
break
}
}
// 虚拟节点中不存在真实节点
if index == -1 {
return nil
}
// 从 member 中删除该真实节点
members = append(members[:index], members[index+1:]...)
// 删除整个元素
err = z.client.ZRemRangeByScore(context.Background(), z.key, score, score).Err()
if err != nil {
return fmt.Errorf("redis ring add fail, err: %w", err)
}
// 如果已经空了,不必再添加
if len(members) == 0 {
return nil
}
// 新建元素
entitiesBytes := z.MarshalEntries(members)
return z.client.ZAdd(context.Background(), z.key, &redis.Z{Score: float64(virtualNode), Member: entitiesBytes}).Err()
}查询节点,总的来说分为两步:
- 查询虚拟节点
- 先查 [hash, +inf) 的第一个节点位置
- 如果没有,为了保持环的状态,再查 (-inf, hash] 的第一个节点位置(这里也间接说明了,为啥相同 score 只能存一个节点,limit 0 1,同 score 只会返回一个节点)
- 查询虚拟节点对应的真实节点
- 如果只有一个真实节点,直接返回
- 如果存在多个真实节点,随机返回一个
// GetNode 根据hash获取节点
// 1. 根据hash找到虚拟节点
// 2. 返回虚拟节点对应的一个真实节点
func (z *ZSetHashRing) GetNode(hash uint64) (string, bool) {
// 找到虚拟节点
members, ok := z.getVirtualNode(hash)
if !ok {
return "", false
}
if len(members) == 1 {
return z.getRawNode(members[0]), true
}
// 如果存在多个,随机一个返回
return members[rand.Intn(len(members))], true
}
// 获取虚拟节点对应的真实节点列表
// 先尝试 [hash, +inf) 区间内的第一个节点(顺时针),如果没找到,再找 (-inf, hash] 区间内的第一个节点(绕一个环回去找)
func (z *ZSetHashRing) getVirtualNode(hash uint64) ([]string, bool) {
zrangeBy := &redis.ZRangeBy{
Min: strconv.FormatUint(hash, 10),
Max: "+inf",
Offset: 0,
Count: 1,
}
// 首先找 [hash, +inf] 区间内的第一个节点
entries, err := z.client.ZRangeByScore(context.Background(), z.key, zrangeBy).Result()
if err != nil && !errors.Is(err, redis.Nil) {
return nil, false
}
if len(entries) != 0 {
return z.UnmarshalEntries(entries), true
}
// 如果没找到,反过来找 [-inf, hash] 区间的第一个节点
zrangeBy.Max = zrangeBy.Min
zrangeBy.Min = "-inf"
entries, err = z.client.ZRangeByScore(context.Background(), z.key, zrangeBy).Result()
if err != nil && !errors.Is(err, redis.Nil) || len(entries) == 0 {
return nil, false
}
return z.UnmarshalEntries(entries), true
}了解了一致性Hash算法的特点后,我们也不难发现一些不尽人意的地方:
- 整个集群还需要一个路由服务来做负载均衡,且路由服务本身存在单点故障
- 环上的虚拟节点数量和真实节点成线性,当节点非常多或者更新频繁时,查询效率很低
Redis 通过基于 P2P 的HashSlot算法,使得每个真实节点都可以作为路由进行转发,也限定了虚拟节点上限。
类似于一致性哈希环,Redis Cluster 采用 HashSlot 来实现 key 值的均匀分布和实例节点的扩缩容管理。
首先默认分配了 16384 个 Slot(相当于一致性哈希环中的虚拟节点),接入集群的所有实例将均匀占用这些 Slot(前面的一致性哈希算法中,都是真实节点去产生虚拟节点,Redis Cluster相当于真实节点均分虚拟节点)。
当我们 Set/Get 一个 Key 时,使用 CRC16(key) mod 16384计算得出这个 Key 属于哪个 Slot,再根据 slot 找到对应的真实实例上(和一致性哈希算法一样,通过哈希函数计算 key,再去环上找虚拟节点,再根据虚拟节点找真实节点)
当节点扩缩容时,Slot 和对应的节点映射关系将发生改变。例如原本只有3个节点A、B、C,那么 slot 和对应节点的映射可能为:
节点A 0-5460
节点B 5461-10922
节点C 10923-16383现在如果增加一个节点 D,Redis Cluster 不仅需要将其他节点的 Slot 移动到 D 上,还需要将之前这些 Slot 中的数据也迁移到 D,成功接入后 Slot 的覆盖情况将变成:
节点A 1365-5460
节点B 6827-10922
节点C 12288-16383
节点D 0-1364,5461-6826,10923-12287同理,删除一个节点后,也就是将其占有的 Slot 及其对应的数据均匀地归还给其他节点。
Redis Cluster 中,每个节点都可以提供路由功能,原因如下:
- 每个节点都保存完整的 HashSlot 到节点的映射表
- 无论向哪个节点发出寻找 Key 的请求,该节点都会通过
CRC16(key) mod 16384算出该 key 的 Slot,并将请求转发至该 Slot 所在的节点
总结一下就是两个要点:映射表和内部转发,这是通过著名的Gossip协议来实现的。 对比一下,HashSlot + P2P的方案解决了去中心化的问题,同时也提供了更好的动态扩展性。但相比于一致性Hash而言,其结构更加复杂,实现上也更加困难。
- 一致性哈希算法是为了让服务节点扩容缩容时,尽量少的进行数据迁移
- 原始的一致性哈希算法可能导致数据倾斜,缩容时可能打垮下一个节点,引入了虚拟节点。将数据尽量均匀落在全部服务节点,缩容时尽量将数据落在剩下节点中。
- go-zero 中直接使用切片存储虚拟节点,可以使用更高效的数据结构例如红黑树、跳表等
- 也可以使用 redis 的 zset 存储哈希环。
- redis 中的 HashSlot + P2P 在一致性哈希算法的基础上,解决了去中心化的问题
https://zhuanlan.zhihu.com/p/653210271 https://zhuanlan.zhihu.com/p/654778311 https://juejin.cn/post/7030436979464470541 https://blog.csdn.net/monokai/article/details/106626945 https://www.bilibili.com/video/BV1Hs411j73w https://www.bilibili.com/video/BV1fF41127pg https://www.bilibili.com/video/BV1F94y1a7fA https://www.bilibili.com/video/BV13R4y1v7sP https://redis.io/docs/reference/cluster-spec/