- - News + Latest changes
-
diff --git a/docs/articles/calibration-data-v2.html b/docs/articles/calibration-data-v2.html
new file mode 100644
index 00000000..e8358adb
--- /dev/null
+++ b/docs/articles/calibration-data-v2.html
@@ -0,0 +1,563 @@
+
+
+
+
+
+
+
+
gbif4crest calibration dataset v2 for CREST • crestr + + + + + + + + + + + + +++ + + + + + + + diff --git a/docs/articles/calibration-data-v3.html b/docs/articles/calibration-data-v3.html new file mode 100644 index 00000000..7d8f7790 --- /dev/null +++ b/docs/articles/calibration-data-v3.html @@ -0,0 +1,568 @@ + + + + + + + ++ + + + + ++ + + + +++ + + +++ + + +gbif4crest calibration dataset v2 for CREST
+Manuel +Chevalier
+ +2025-01-22
+ + Source:vignettes/calibration-data-v2.Rmd++ +calibration-data-v2.Rmd++Source of the calibration data +
+A multiproxy calibration dataset to estimate PDFs from a global +collection of geolocalised presence-only data (hereafter proxy +distributions) was first presented in [1]. +These data were obtained from the Global Biodiversity Information Facility (GBIF) +database, an online collection of geolocalised observations of +biological entities. The calibration dataset (hereafter +gbif4crest) contains the species distributions of six common +palaeoecological fossil: the five taxa presented in the original version +of the dataset — plants [2-12] for fossil pollen and +macrofossils, chironomids [13], +beetles [14], diatoms [15] and foraminifera [16] – to which rodents [17] were recently added (Fig. +1).
+++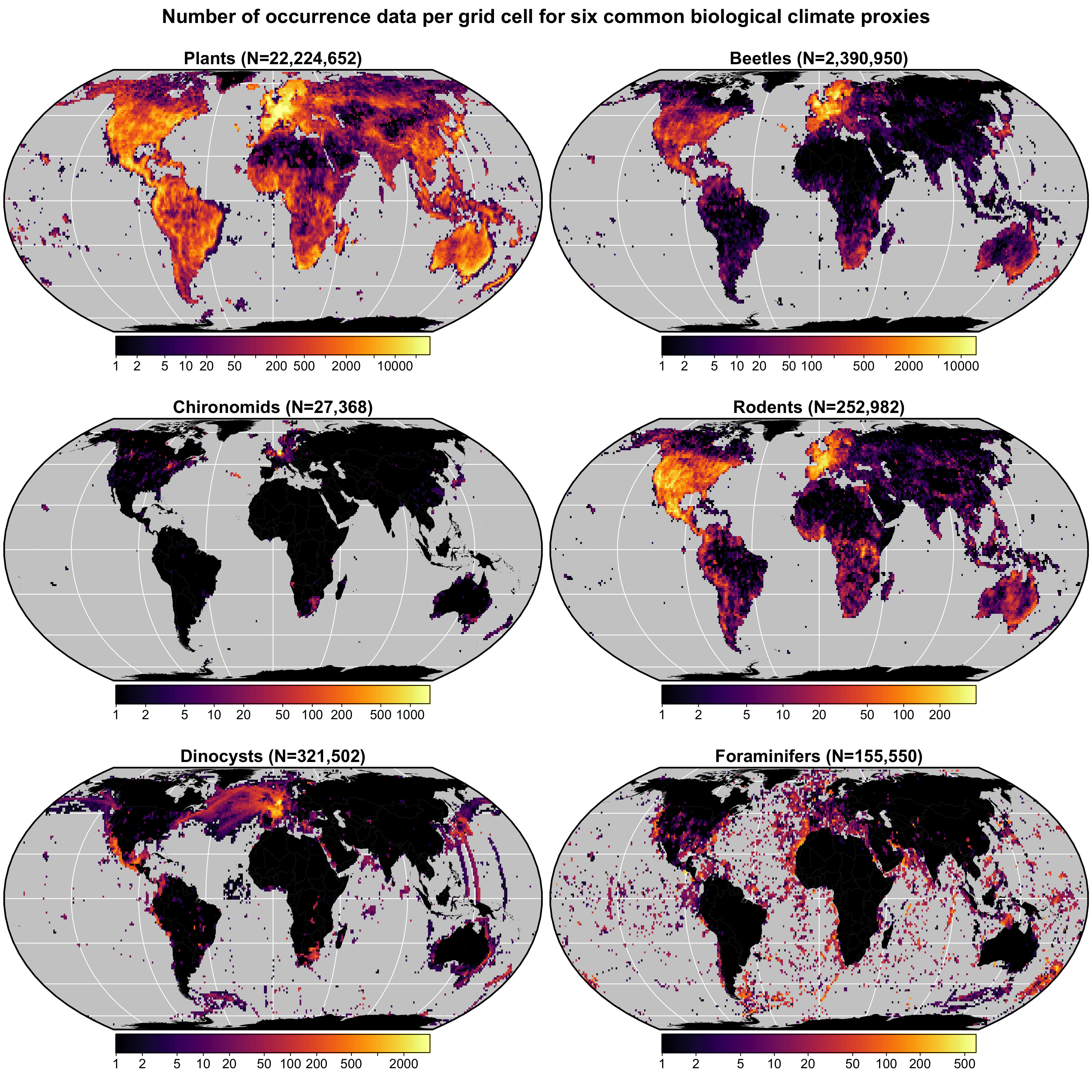
+Fig. 1 Data density of the six climate proxies +available in the gbif4crest calibration database. The total number of +unique species occurrences (N) is indicated for each proxy. The maps are +based on the ‘Equal Earth’ map projection to better account for the +relative sizes of the different continents. +
+
+The coordinates of all the presence records of these six common +palaeoecological fossil proxies were upscaled at a spatial resolution of +0.25 x 0.25° (hereafter QDGC for Quarter-Degree Grid Cell) and +subsequently associated with terrestrial and oceanic environmental +variables at the same resolution [18-24] (see details in Table 1). +The QDGC spatial resolution is an empirical trade-off between numerous +factors, including the resolution of the presence data, the quality of +the data or the spatial representativity of the studied proxy. However, +this tradeoff may be suboptimal in some situations, and for that reason, +
+crestrcan also be used with the raw GBIF data and even +alternative calibration datasets.In its current version (V2), the gbif4crest calibration +dataset contains about 25.3 million unique presence data for the six +proxies. Unfortunately, the density of available data varies strongly +between proxies and regions (Fig. 1). Plant data +dominate the calibration dataset (>22 million unique occurrences) and +allow for the use of
+crestracross all landmasses where +vegetation currently grows. For the five other proxies, the datasets are +still incomplete in many regions, restricting the use of +crestr(e.g. chironomids). However, these datasets +are regularly updated by GBIF. For example, the first version of the +gbif4crest dataset released in 2018 contained about 17.5 +million QDGC entries, but the new version presented here contains nearly +25.3 million entries (~44% increase). The range of ‘reconstructible’ +areas is thus rapidly broadening (see, for instance, the coverage of +Russia by plant data compared to the first version of the +gbif4crest dataset [1].
+Table 1 List of terrestrial and marine variables +available in the gbif4crest database. Each one can be selected +in crestr using its associated code. List of abbreviations: (Temp.) +Temperature, (Precip.) Precipitation, (SST) Sea Surface Temperature, +(SSS) Sea Surface Salinity.
++
++ ++ + + + + +Code +Full name +Source ++ +bio1 +Mean Annual Temp. (°C) +[18] ++ +bio2 +Mean Diurnal Range (°C) +[18] ++ +bio3 +Isothermality (x100) +[18] ++ +bio4 +Temp. Seasonality (standard deviation x100) (°C) +[18] ++ +bio5 +Max Temp. of the Warmest Month (°C) +[18] ++ +bio6 +Min Temp. of the Coldest Month (°C) +[18] ++ +bio7 +Temp. Annual Range (°C) +[18] ++ +bio8 +Mean Temp. of the Wettest Quarter (°C) +[18] ++ +bio9 +Mean Temp. of the Driest Quarter (°C) +[18] ++ +bio10 +Mean Temp. of the Warmest Quarter (°C) +[18] ++ +bio11 +Mean Temp. of the Coldest Quarter (°C) +[18] ++ +bio12 +Annual precip. (mm) +[18] ++ +bio13 +Precip. of the Wettest Month (mm) +[18] ++ +bio14 +Precip. of the Driest Month (mm) +[18] ++ +bio15 +Precip. Seasonality (Coefficient of Variation) (mm) +[18] ++ +bio16 +Precip. of the Wettest Quarter (mm) +[18] ++ +bio17 +Precip. of the Driest Quarter (mm) +[18] ++ +bio18 +Precip. of the Warmest Quarter (mm) +[18] ++ +bio19 +Precip. of the Coldest Quarter (mm) +[18] ++ +ai +Aridity Index (unitless) +[19] ++ +sst_ann +Mean Annual SST (°C) +[20] ++ +sst_jfm +Mean Winter SST (°C) +[20] ++ +sst_amj +Mean Spring SST (°C) +[20] ++ +sst_jas +Mean Summer SST (°C) +[20] ++ +sst_ond +Mean Fall SST (°C) +[20] ++ +sss_ann +Mean Annual SSS (PSU) +[21] ++ +sss_jfm +Mean Winter SSS (PSU) +[21] ++ +sss_amj +Mean Spring SSS (PSU) +[21] ++ +sss_jas +Mean Summer SSS (PSU) +[21] ++ +sss_ond +Mean Fall SSS (PSU) +[21] ++ +diss_oxy +Dissolved Oxygen Concentration (mol/L) +[22] ++ +nitrate +Nitrate Concentration (mol/L) +[23] ++ +phosphate +Phosphate Concentration (mol/L) +[23] ++ +silicate +Silicate Concentration (mol/L) +[23] ++ +icec_ann +Mean Annual Sea Ice Concentration (%) +[24] ++ +icec_jfm +Mean Winter Sea Ice Concentration (%) +[24] ++ +icec_amj +Mean Spring Sea Ice Concentration (%) +[24] ++ +icec_jas +Mean Summer Ice Concentration (%) +[24] ++ + +icec_ond +Mean Fall Sea Ice Concentration (%) +[24] +
+++Processing and storage of the calibration data +
+All these data were curated in a relational database to ensure the +consistency of the data (Fig. 2). The +gbif4crest database is composed of three main types of data: +taxonomic data (
+TAXAtable on Fig. 2), +distribution data (DISTRIBandDISTRIB_QDGC+tables) and diverse geopolitical, climatological and environmental data +(DATA_QDGCtable). Its structure is slightly different from +the first version, with a grouping of all the distinct QDGC tables in a +uniqueDATA_QDGCtable to enable a faster data extraction. +Additional environmental and geographical descriptors were added to +characterise each grid cell and enable a more refined data selection. +These include elevation and elevation variability [25], the country (www.naturalearthdata.com) or ocean (www.marineregions.org) names, as well as different +levels of ecological classification for the terrestrial [26] and marine [27] +realms. The first and last observation dates are also now included, +along with the type of observation, as reported by GBIF (see +DISTRIB_QDGCtable on Fig. 2). Finally, +theDATAtable was entirely recalculated using a new +protocol that better accounts for coastal margins. Climate values at +some locations are thus expected to be slightly different from the first +version of the gbif4crest dataset.
+++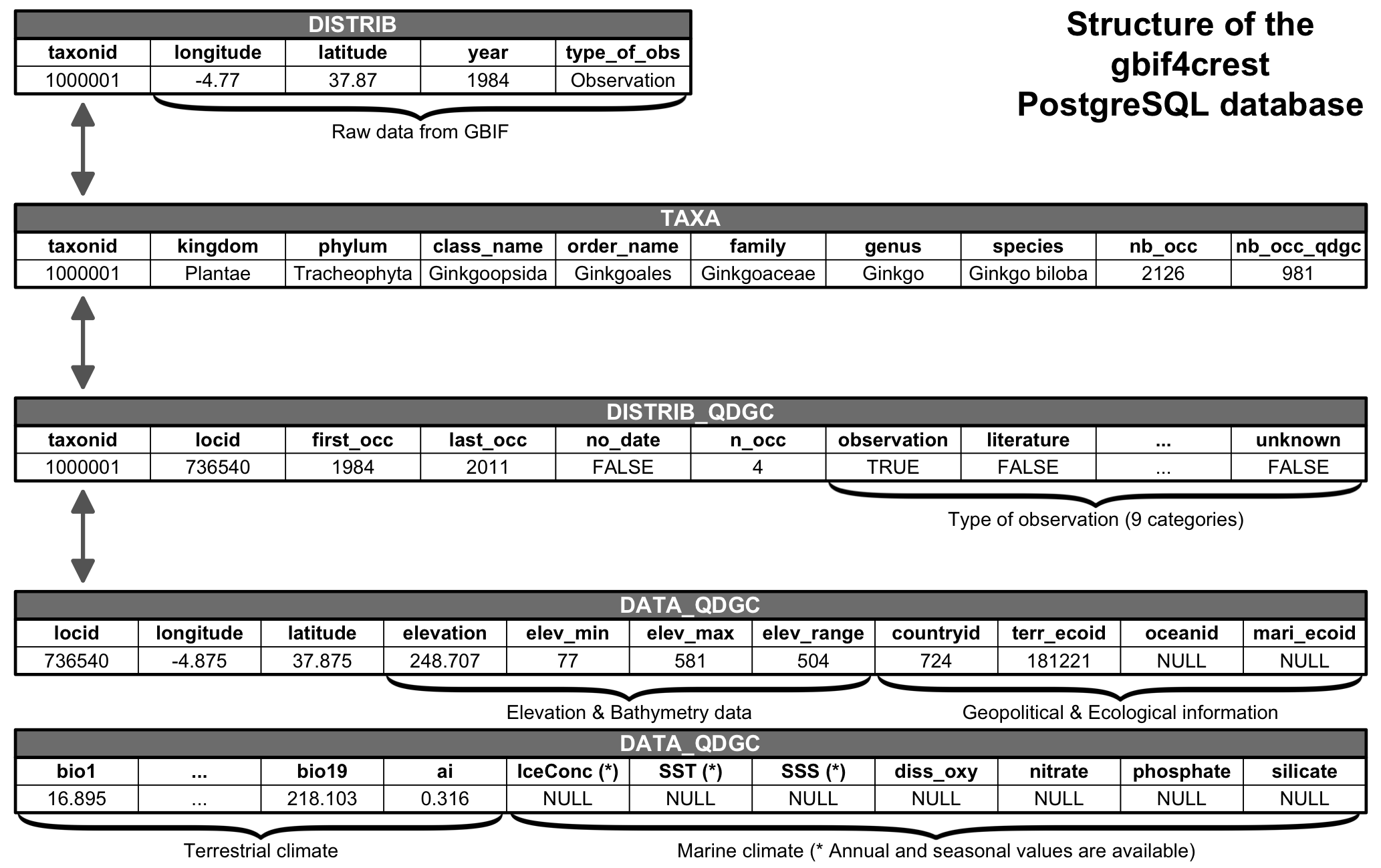
+FiG. 2 Structure of the gbif4crest PostgreSQL database. +By default, the package extracts data from the TAXA, DISTRIB-QDGC and +DATA-QDGC tables. The DISTRIB table contains the raw occurrence data and +can be used to process the data at a different spatial resolution for +example. +
+
+Due to its large size (about 23 Gb), this database is not downloaded +when installing the package, but it can be assessed differently. First, +the data are stored in an open-access, cloud-based PostgreSQL database +that can be dynamically accessed via
+crestr. Second, the +database can also be downloaded as a SQLite3 file format from here to work offline. No a priori SQL +knowledge is required to use any of these two options, so that users can +benefit from the package’s interface to automatically query the database +simply by providing study-specific parameters, such as the name of the +taxa or boundaries for the study area, to import all the necessary data +in the correct format to the R environment. Alternatively, advanced +users can also directly query the database to extract and curate data +from theDISTRIBorDISTRIB_QDGCtables using +the dbRequest() +function, and subsequently associate these data with climate +variables.
+++References +
+[1] Chevalier, M., 2019. +Enabling possibilities to quantify past climate from fossil assemblages +at a global scale. Global and Planetary Change, 175, pp. 27–35. doi:10.1016/j.earscirev.2020.103384.
+[2] GBIF, 2020, +Anthocerotopsida occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.t9zenf.
+[3] GBIF, 2021, +Bryophyta occurrence data downloaded on August 2nd, 2021. doi:10.15468/DL.WD527G.
+[4] GBIF, 2020, +Cycadopsidae occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.sfjzxu.
+[5] GBIF, 2020, +Gingkoopsidae occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.da9wz8.
+[6] GBIF, 2020, +Gnetopsidae occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.h2kjnc.
+[7] GBIF, 2020, +Liliopsida occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.axv3yd.
+[8] GBIF, 2020, +Lycopodiopsida occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.ydhyhz.
+[9] GBIF, 2020, +Magnoliopsida occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.ra49dt.
+[10] GBIF, 2021, +Marchantiophyta occurrence data downloaded on August 2nd, 2021. doi:10.15468/DL.M2SSE4.
+[11] GBIF, 2020, +Pinopsidae occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.x2r7pa.
+[12] GBIF, 2020, +Polypodiopsida occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.87tbp6.
+[13] GBIF, 2020, +Chironomids occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.jv3wsh.
+[14] GBIF, 2020, Beetles +occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.nteruy.
+[15] GBIF, 2020, Diatoms +occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.vfr257.
+[16] GBIF, 2020, +Foraminifera occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.692yg6.
+[17] GBIF, 2020, +Rodentia occurrence data downloaded on September 24th, 2020. doi:10.15468/dl.fscw6q.
+[18] Fick, S.E. and +Hijmans, R.J., 2017, WorldClim 2: new 1-km spatial resolution climate +surfaces for global land areas. International Journal of Climatology, +37, pp. 4302–4315. doi:10.1002/joc.5086.
+[19] Zomer, R.J., Trabucco, +A., Bossio, D.A. and Verchot, L. V., 2008, Climate change mitigation: A +spatial analysis of global land suitability for clean development +mechanism afforestation and reforestation. Agriculture, Ecosystems & +Environment, 126, pp. 67–80. doi:10.1016/j.agee.2008.01.014.
+[20] Locarnini, R.A., +Mishonov, A.V., Baranova, O.K., Boyer, T.P., Zweng, M.M., Garcia, H.E., +Reagan, J.R., Seidov, D., Weathers, K.W., Paver, C.R., Smolyar, I.V. and +Others, 2019, World ocean atlas 2018, volume 1: Temperature. NOAA Atlas +NESDIS 81, pp. 52pp. data access.
+[21] Zweng, M.M., +Seidov, D., Boyer, T.P., Locarnini, R.A., Garcia, H.E., Mishonov, A.V., +Baranova, O.K., Weathers, K.W., Paver, C.R., Smolyar, I.V. and Others, +2018, World Ocean Atlas 2018, Volume 2: Salinity. NOAA Atlas NESDIS 82, +pp. 50pp. data access.
+[22] Garcia, H.E., +Weathers, K.W., Paver, C.R., Smolyar, I.V., Boyer, T.P., Locarnini, +R.A., Zweng, M.M., Mishonov, A.V., Baranova, O.K., Seidov, D. and +Reagan, J.R., 2019, World Ocean Atlas 2018, Volume 3: Dissolved Oxygen, +Apparent Oxygen Utilization, and Dissolved Oxygen Saturation.. NOAA +Atlas NESDIS 83, pp. 38pp. data access.
+[23] Garcia, H.E., +Weathers, K.W., Paver, C.R., Smolyar, I.V., Boyer, T.P., Locarnini, +R.A., Zweng, M.M., Mishonov, A.V., Baranova, O.K., Seidov, D., Reagan, +J.R. and Others, 2019, World Ocean Atlas 2018. Vol. 4: Dissolved +Inorganic Nutrients (phosphate, nitrate and nitrate+nitrite, silicate). +NOAA Atlas NESDIS 84, pp. 35pp. data access.
+[24] Reynolds, R.W., +Smith, T.M., Liu, C., Chelton, D.B., Casey, K.S. and Schlax, M.G., 2007, +Daily high-resolution-blended analyses for sea surface temperature. +Journal of Climate, 20, pp. 5473–5496. doi:10.1175/2007JCLI1824.1.
+[25] Amante, C. and Eakins, B.W., +2009, Etopo1 1 Arc-Minute Global Relief Model: Procedures, Data Sources +and Analysis. NOAA Technical Memorandum NESDIS NGDC-24. National +Geophysical Data Center, NOAA. doi:10.7289/V5C8276M.
+[26] Olson, D.M., Dinerstein, +E., Wikramanayake, E.D., Burgess, N.D., Powell, G.V.N., Underwood, E.C., +D’amico, J.A., Itoua, I., Strand, H.E., Morrison, J.C., Loucks, C.J., +Allnutt, T.F., Ricketts, T.H., Kura, Y., Lamoreux, J.F., Wettengel, +W.W., Hedao, P. and Kassem, K.R., 2001, Terrestrial Ecoregions of the +World: A New Map of Life on Earth: A new global map of terrestrial +ecoregions provides an innovative tool for conserving biodiversity. +BioScience, 51, pp. 933. doi:10.1641/0006-3568(2001)051[0933:TEOTWA]2.0.CO;2.
+[27] Costello, M.J., Tsai, +P., Wong, P.S., Cheung, A.K.L., Basher, Z. and Chaudhary, C., 2017, +Marine biogeographic realms and species endemicity. Nature +Communications, 8, pp. 1–9. doi:10.1038/s41467-017-01121-2.
+
+gbif4crest calibration dataset v3 for CREST • crestr + + + + + + + + + + + + +++ + + + + + + + diff --git a/docs/articles/calibration-data.html b/docs/articles/calibration-data.html index 0aafee30..7f66a9cd 100644 --- a/docs/articles/calibration-data.html +++ b/docs/articles/calibration-data.html @@ -5,13 +5,13 @@ -+ + + + + ++ + + + +++ + + +++ + + +gbif4crest calibration dataset v3 for CREST
+Manuel +Chevalier
+ +2025-01-22
+ + Source:vignettes/calibration-data-v3.Rmd++ +calibration-data-v3.Rmd++What is this this dataset and should I it? +
+I developed this calibration dataset to enable the use of +crestr in many regions for many proxies (See Fig. +1). In previous version, there were also distribution data for +insects. I did not include such data in the new calibration dataset +because some (palaeo)entomologists mentioned that the large-scale +climatologies I used to assign climate values to each grid cell (see +below) do not reflect the local environments / microclimates many +insects experience.
+Should you use this dataset? Only if you want to. +You do not have to use it if you have access to appropriate calibration +data that have important properties for your analysis. In such cases, I +recommend using such data over which you have total control and skipping +the gbif4crest calibration data. In addition, CREST can be used +with many proxies for which I did not compile data, provided that their +spatial distribution can be related to climate parameters to +reconstruct.
+
+++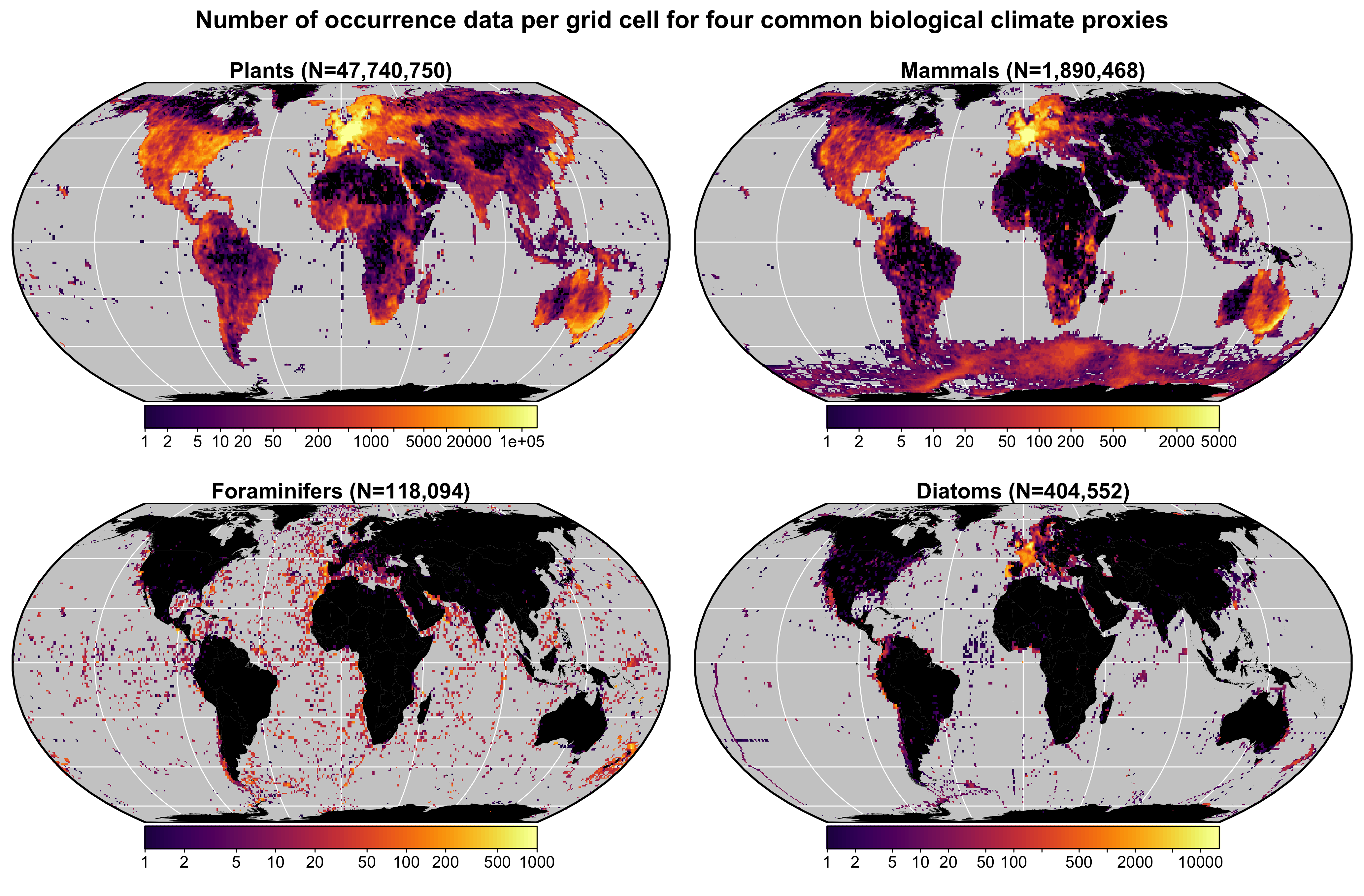
+Fig. 1 Data density of the four climate proxies +available in the gbif4crest calibration database. The total number of +unique species occurrences (N) is indicated for each proxy. The maps are +based on the ‘Equal Earth’ map projection to better account for the +relative sizes of the different continents. +
+
+++Source of the calibration data +
+A multiproxy calibration dataset to estimate PDFs from a global +collection of geolocalised presence-only data (hereafter proxy +distributions) was first presented in [1]. +These data were obtained from the Global Biodiversity Information Facility (GBIF) +database, an online collection of geolocalised observations of +biological entities [2-10].
+The coordinates of all the presence records of these four common +palaeoecological fossil proxies were upscaled at a spatial resolution of +1/12° (roughly 0.0833°) and subsequently associated with terrestrial and +oceanic environmental variables at the same resolution [11-17] (see +details in Table 1). The spatial resolution is an +empirical trade-off between numerous factors, including the resolution +of the presence data, the quality of the data or the spatial +representativity of the studied proxy. However, this tradeoff may be +suboptimal in some situations, and may be a reason to consider using +another calibration dataset.
+In its current version (V3), the gbif4crest calibration +dataset contains about 50 million unique presence data for four proxies. +Unfortunately, the density of available data varies strongly between +proxies and regions (Fig. 1). Plant data dominate the +calibration dataset (>47 million unique occurrences) and allow for +the use of
+crestracross all landmasses where vegetation +currently grows. For the proxies, the datasets are still incomplete in +many regions, restricting the use ofcrestr(e.g. +mammals across most of Asia). However, these datasets are regularly +updated by GBIF. For example, the first version of the +gbif4crest dataset released in 2018 contained about 17.5 +million QDGC entries, the second version about 25.3 and the latest +version presented here contains nearly 50 million entries (~300% +increase in about 6 years). The range of ‘reconstructible’ areas is thus +rapidly broadening (see, for instance, the coverage of Russia by plant +data compared to the first version of the gbif4crest dataset [1].
+Table 1 List of terrestrial and marine variables +available in the gbif4crest database. Each one can be selected +in crestr using its associated code. List of abbreviations: (Temp.) +Temperature, (Precip.) Precipitation, (SST) Sea Surface Temperature, +(SSS) Sea Surface Salinity.
++
++ ++ + + + + +Code +Full name +Source ++ +bio1 +Mean Annual Temp. (°C) +[11] ++ +bio2 +Mean Diurnal Range (°C) +[11] ++ +bio3 +Isothermality (x100) +[11] ++ +bio4 +Temp. Seasonality (standard deviation x100) (°C) +[11] ++ +bio5 +Max Temp. of the Warmest Month (°C) +[11] ++ +bio6 +Min Temp. of the Coldest Month (°C) +[11] ++ +bio7 +Temp. Annual Range (°C) +[11] ++ +bio8 +Mean Temp. of the Wettest Quarter (°C) +[11] ++ +bio9 +Mean Temp. of the Driest Quarter (°C) +[11] ++ +bio10 +Mean Temp. of the Warmest Quarter (°C) +[11] ++ +bio11 +Mean Temp. of the Coldest Quarter (°C) +[11] ++ +bio12 +Annual precip. (mm) +[11] ++ +bio13 +Precip. of the Wettest Month (mm) +[11] ++ +bio14 +Precip. of the Driest Month (mm) +[11] ++ +bio15 +Precip. Seasonality (Coefficient of Variation) (mm) +[11] ++ +bio16 +Precip. of the Wettest Quarter (mm) +[11] ++ +bio17 +Precip. of the Driest Quarter (mm) +[11] ++ +bio18 +Precip. of the Warmest Quarter (mm) +[11] ++ +bio19 +Precip. of the Coldest Quarter (mm) +[11] ++ +ai +Aridity Index (unitless) +[12] ++ +sst_ann +Mean Annual SST (°C) +[13] ++ +sst_jfm +Mean Winter SST (°C) +[13] ++ +sst_amj +Mean Spring SST (°C) +[13] ++ +sst_jas +Mean Summer SST (°C) +[13] ++ +sst_ond +Mean Fall SST (°C) +[13] ++ +sss_ann +Mean Annual SSS (PSU) +[14] ++ +sss_jfm +Mean Winter SSS (PSU) +[14] ++ +sss_amj +Mean Spring SSS (PSU) +[14] ++ +sss_jas +Mean Summer SSS (PSU) +[14] ++ +sss_ond +Mean Fall SSS (PSU) +[14] ++ +diss_oxy +Dissolved Oxygen Concentration (mol/L) +[15] ++ +nitrate +Nitrate Concentration (mol/L) +[16] ++ +phosphate +Phosphate Concentration (mol/L) +[16] ++ +silicate +Silicate Concentration (mol/L) +[16] ++ +icec_ann +Mean Annual Sea Ice Concentration (%) +[17] ++ +icec_jfm +Mean Winter Sea Ice Concentration (%) +[17] ++ +icec_amj +Mean Spring Sea Ice Concentration (%) +[17] ++ +icec_jas +Mean Summer Ice Concentration (%) +[17] ++ + +icec_ond +Mean Fall Sea Ice Concentration (%) +[17] +
+++Processing and storage of the calibration data +
+All these data were curated in a relational database to ensure the +consistency of the data (Fig. 2). The +gbif4crest database is composed of three main types of data: +taxonomic data (
+TAXAtable on Fig. 2), +distribution data (DISTRIBandDISTRIB_QDGC+tables) and diverse geopolitical, climatological and environmental data +(DATA_QDGCtable). Additional environmental and +geographical descriptors were included to characterise each grid cell +and enable a more refined data selection. These include elevation and +elevation variability [18], the country (www.naturalearthdata.com) or ocean (www.marineregions.org) names, as well as different +levels of ecological classification for the terrestrial [19] and marine [20] +realms. The first and last observation dates are also now included, +along with the type of observation, as reported by GBIF (see +DISTRIB_QDGCtable on Fig. 2). Finally, +theDATAtable was entirely recalculated using a new +protocol that better accounts for coastal margins. Climate values at +some locations are thus expected to be slightly different from the first +version of the gbif4crest dataset.
++++FiG. 2 Structure of the gbif4crest PostgreSQL database. +By default, the package extracts data from the TAXA, DISTRIB-QDGC and +DATA-QDGC tables. The DISTRIB table contains the raw occurrence data and +can be used to process the data at a different spatial resolution for +example. +
+
+Due to its large size, this database is not downloaded when +installing the package, but it can be downloaded as a SQLite3 file +format from here. No a priori SQL knowledge is required +to use the database, so that users can benefit from the package’s +interface to automatically query the database simply by providing +study-specific parameters, such as the name of the taxa or boundaries +for the study area, to import all the necessary data in the correct +format to the R environment. Alternatively, advanced users can also +directly query the database to extract and curate data from the +
+DISTRIBorDISTRIB_QDGCtables using the dbRequest() +function, and subsequently associate these data with climate variables. +Also check the “Using the gbif4crest database” page under the More +section.
+++References +
+[1] Chevalier, M., 2019. +Enabling possibilities to quantify past climate from fossil assemblages +at a global scale. Global and Planetary Change, 175, pp. 27–35. doi:10.1016/j.earscirev.2020.103384.
+[2] The Global +Biodiversity Information Facility, 2024. Occurrence data downloaded on +25 August 2024. doi:10.15468/dl.ZGMNQ9.
+[3] The Global +Biodiversity Information Facility, 2024. Occurrence data downloaded on +25 August 2024. doi:10.15468/dl.Y9KPWC.
+[4] The Global +Biodiversity Information Facility, 2024. Occurrence data downloaded on +25 August 2024. doi:10.15468/dl.UK2XV6.
+[5] The Global +Biodiversity Information Facility, 2024. Occurrence data downloaded on +25 August 2024. doi:10.15468/dl.QWCS68.
+[6] The Global +Biodiversity Information Facility, 2024. Occurrence data downloaded on +25 August 2024. doi:10.15468/dl.Q8ZUHH.
+[7] The Global +Biodiversity Information Facility, 2024. Occurrence data downloaded on +25 August 2024. doi:10.15468/dl.NUQ5TN.
+[8] The Global +Biodiversity Information Facility, 2024. Occurrence data downloaded on +25 August 2024. doi:10.15468/dl.MPFC47.
+[9] The Global +Biodiversity Information Facility, 2024. Occurrence data downloaded on +25 August 2024. doi:10.15468/dl.68HQXG.
+[10] The Global +Biodiversity Information Facility, 2024. Occurrence data downloaded on +25 August 2024. doi:10.15468/dl.7BVEJK.
+[11] Fick, S.E. and +Hijmans, R.J., 2017, WorldClim 2: new 1-km spatial resolution climate +surfaces for global land areas. International Journal of Climatology, +37, pp. 4302–4315. doi:10.1002/joc.5086.
+[12] Zomer, R.J., Trabucco, +A., Bossio, D.A. and Verchot, L. V., 2008, Climate change mitigation: A +spatial analysis of global land suitability for clean development +mechanism afforestation and reforestation. Agriculture, Ecosystems & +Environment, 126, pp. 67–80. doi:10.1016/j.agee.2008.01.014.
+[13] Locarnini, R.A., +Mishonov, A.V., Baranova, O.K., Boyer, T.P., Zweng, M.M., Garcia, H.E., +Reagan, J.R., Seidov, D., Weathers, K.W., Paver, C.R., Smolyar, I.V. and +Others, 2019, World ocean atlas 2018, volume 1: Temperature. NOAA Atlas +NESDIS 81, pp. 52pp. data access.
+[14] Zweng, M.M., +Seidov, D., Boyer, T.P., Locarnini, R.A., Garcia, H.E., Mishonov, A.V., +Baranova, O.K., Weathers, K.W., Paver, C.R., Smolyar, I.V. and Others, +2018, World Ocean Atlas 2018, Volume 2: Salinity. NOAA Atlas NESDIS 82, +pp. 50pp. data access.
+[15] Garcia, H.E., +Weathers, K.W., Paver, C.R., Smolyar, I.V., Boyer, T.P., Locarnini, +R.A., Zweng, M.M., Mishonov, A.V., Baranova, O.K., Seidov, D. and +Reagan, J.R., 2019, World Ocean Atlas 2018, Volume 3: Dissolved Oxygen, +Apparent Oxygen Utilization, and Dissolved Oxygen Saturation.. NOAA +Atlas NESDIS 83, pp. 38pp. data access.
+[16] Garcia, H.E., +Weathers, K.W., Paver, C.R., Smolyar, I.V., Boyer, T.P., Locarnini, +R.A., Zweng, M.M., Mishonov, A.V., Baranova, O.K., Seidov, D., Reagan, +J.R. and Others, 2019, World Ocean Atlas 2018. Vol. 4: Dissolved +Inorganic Nutrients (phosphate, nitrate and nitrate+nitrite, silicate). +NOAA Atlas NESDIS 84, pp. 35pp. data access.
+[17] Reynolds, R.W., +Smith, T.M., Liu, C., Chelton, D.B., Casey, K.S. and Schlax, M.G., 2007, +Daily high-resolution-blended analyses for sea surface temperature. +Journal of Climate, 20, pp. 5473–5496. doi:10.1175/2007JCLI1824.1.
+[18] Amante, C. and Eakins, B.W., +2009, Etopo1 1 Arc-Minute Global Relief Model: Procedures, Data Sources +and Analysis. NOAA Technical Memorandum NESDIS NGDC-24. National +Geophysical Data Center, NOAA. doi:10.7289/V5C8276M.
+[19] Olson, D.M., Dinerstein, +E., Wikramanayake, E.D., Burgess, N.D., Powell, G.V.N., Underwood, E.C., +D’amico, J.A., Itoua, I., Strand, H.E., Morrison, J.C., Loucks, C.J., +Allnutt, T.F., Ricketts, T.H., Kura, Y., Lamoreux, J.F., Wettengel, +W.W., Hedao, P. and Kassem, K.R., 2001, Terrestrial Ecoregions of the +World: A New Map of Life on Earth: A new global map of terrestrial +ecoregions provides an innovative tool for conserving biodiversity. +BioScience, 51, pp. 933. doi:10.1641/0006-3568(2001)051[0933:TEOTWA]2.0.CO;2.
+[20] Costello, M.J., Tsai, +P., Wong, P.S., Cheung, A.K.L., Basher, Z. and Chaudhary, C., 2017, +Marine biogeographic realms and species endemicity. Nature +Communications, 8, pp. 1–9. doi:10.1038/s41467-017-01121-2.
+
+Calibration data for CREST • crestr +gbif4crest calibration data for CREST • crestr - + - +Identify the calibration database used. — identifyDatabase • crestr + + +++ + + + + + + + diff --git a/docs/reference/includeTaxa.html b/docs/reference/includeTaxa.html index 4eff9f8e..6b5bf491 100644 --- a/docs/reference/includeTaxa.html +++ b/docs/reference/includeTaxa.html @@ -17,7 +17,7 @@ @@ -38,32 +38,32 @@ Prepare your data+ + + + ++ + ++ + ++ +++ +Identify the calibration database used.
+++ ++identifyDatabase(dbname)++Arguments
+- dbname +
A functional crestObj or a database name.
+
+
++ +Value
+ + +A string uniquely characterising the database used. Possible values +are 'privateDB', 'exampleDB', 'gbif4crest_02', and 'gbif4crest_03'.
+++Examples
++identifyDatabase(reconstr) +#> [1] "exampleDB" + + - - Calibration data + Dive into gbif4crest
- - Reference - -
- - Community + Take the control
- - Vignettes + More