A la hora de recopilar datos de libre acceso, alojados en sitios web de entidades y/o instituciones gubernamentales, es deseable obtenerlos en un "formato consumible" (xlsx,csv,sav, etc.) por el usuario, pero no siempre es posible. Para superar este inconveniente de manera eficiente, existen técnicas como el Web Scraping, que básicamente consiste en explorar el código fuente, identificar y extraer la información que sea considerada relevante para los fines deseados. Se dice que es eficiente porque una vez generado el script, es un proceso automatizado y replicable. En este caso, utilizando Python se desea obtener los datos de Covid-19 a nivel de países de todo el mundo.
- Requerimientos (Requirements)
- Optención de datos (Data Collection)
- Procesamiento de la data (Data Processing)
- Exploración y análisis (Exploratory Data Analysis)
Algunas estrategias de Web Scraping requieren de algún complemento o software adicional. Para este caso solo se utilza los recursos de dos paquetes de Python. Esto puede variar dependiendo de las características y la estructura de las páginas web.
Para lograr el objetivo, se requiere lo siguiente:
- Como fuente de información, la página web Worldometer.
- El paquete
urllib, los módulosRequestyurlopen. Para abrir, leer y analizar url. - El paquete
bs4, Para extraer los datos del archivo HTML y XML.
Eventualmente los paquetes ya conocidos: pandas, numpy, datetime, matplotliby plotly. Para procesar la Data, definir formato y visualizar mediante gráficos.
Nota. Otras fuentes para obetener datos de Covid-19: Healthdata, Ourworldindata, WorldHealthOrganization.
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup as soup
from datetime import date, datetime
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly.graph_objects as go
import plotly.express as px
import plotly.offline as py
import seaborn as sns
import gc
import warnings
warnings.filterwarnings("ignore")
Los reportes de Worldometer se actualizan a las 00:00 horas de la zona horaria GMT+0. Es decir, a las 19:00 horas de Perú (GMT-5), por lo que los registros de nuevos casos después de dicha hora permanecen vacíos para algunos países, incluyendo los de América. Para obtener la última Data completa de todos los países, es conveniente seleccionar la información del día anterior (En Perú, Data antes de 19:00 hrs).
today = datetime.now()
print(today)
yesterday_str = "%d %s, %d" %(today.day-1, date.today().strftime("%b"), today.year)
yesterday_str
2021-09-18 22:43:23.498026
'17 Sep, 2021'
En el siguiente apartado se realiza la consulta con la línea req = Request(url , headers... , que tiene como argumento la dirección web anteriormente almacenada en la variable url y headersque identifica al navegador. Posteriormente la consulta es aperturada y almacenada en webpage = urlopen(req). Finalmente se visualiza una parte de la estructura de la página web, que previamente fue analizada con BeautifulSoup (sup) y almacenada en page_soup.
url = "https://www.worldometers.info/coronavirus/#countries"
req = Request(url , headers ={'User-Agent': "Chrome/92.0.4515.159"})
webpage = urlopen(req)
print(webpage)
page_soup = soup(webpage, "html.parser")
page_soup.head()
.
.
.
<div aria-labelledby="nav-yesterday-tab" class="tab-pane" id="nav-yesterday" role="tabpanel">
<div class="main_table_countries_div">
<table class="table table-bordered table-hover main_table_countries" id="main_table_countries_yesterday" style="width:100%;margin-top: 0px !important;display:none;">
<thead>
<tr>
<th width="1%">#</th>
<th width="100">Country,<br/>Other</th>
<th width="20">Total<br/>Cases</th>
<th width="30">New<br/>Cases</th>
<th width="30">Total<br/>Deaths</th>
<th width="30">New<br/>Deaths</th>
<th width="30">Total<br/>Recovered</th>
<th width="30">New<br/>Recovered</th>
<th width="30">Active<br/>Cases</th>
<th width="30">Serious,<br/>Critical</th>
<th width="30">Tot Cases/<br/>1M pop</th>
<th width="30">Deaths/<br/>1M pop</th>
<th width="30">Total<br/>Tests</th>
<th width="30">Tests/<br/>
<nobr>1M pop</nobr>
</th>
<th width="30">Population</th>
<th style="display:none" width="30">Continent</th>
<th width="30">1 Case<br/>every X ppl</th><th width="30">1 Death<br/>every X ppl</th><th width="30">1 Test<br/>every X ppl</th>
<th width="30">New Cases/1M pop</th>
<th width="30">New Deaths/1M pop</th>
<th width="30">Active Cases/1M pop</th>
</tr>
</thead>
<tbody>
<tr class="total_row_world row_continent" data-continent="Asia" style="display: none">
<td></td>
<td style="text-align:left;">
<nobr>Asia</nobr>
</td>
<td>73,945,759</td>
<td>+177,798</td>
<td>1,095,522</td>
<td>+2,635</td>
<td>69,870,746</td>
<td>+229,725</td>
<td>2,979,491</td>
<td>37,901</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td data-continent="Asia" style="display:none;">Asia</td>
<td>
</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
</tr>
<tr class="total_row_world row_continent" data-continent="North America" style="display: none">
<td></td>
<td style="text-align:left;">
<nobr>North America</nobr>
</td>
<td>51,470,978</td>
<td>+85,293</td>
<td>1,045,930</td>
<td>+1,236</td>
<td>39,730,650</td>
<td>+71,043</td>
<td>10,694,398</td>
<td>32,360</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td data-continent="North America" style="display:none;">North America</td>
<td>
.
.
.
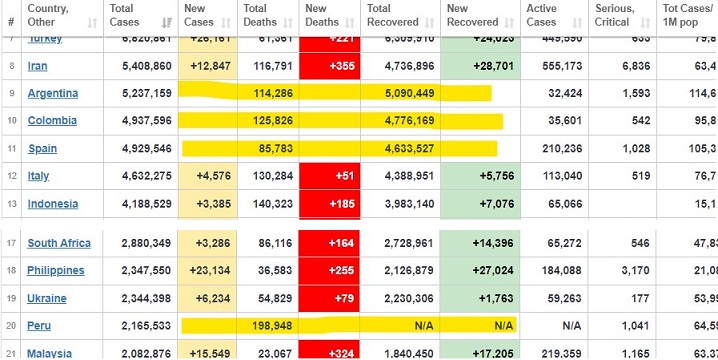
A lo largo de código almacenado en page_soup, mediante el atributo table e identificador id se localiza la tabla que contiene la información a extraer, en este caso main_table_countries_yesterday. En adelante, en vista de que cada fila corresponde a un país, con findAll y el atributo td se establece una secuencia de instrucciones o loop para reemplazar los valores no existentes o no deseados, y así únicamente extraer los datos de nuestro interés, los cuales se adjuntan dentro del elemento all_data
table = page_soup.findAll("table",{"id":"main_table_countries_yesterday"})
containers = table[0].findAll("tr",{"style":""})
title = containers[0]
del containers[0]
all_data =[]
clean = True
for country in containers:
country_data = []
country_container = country.findAll("td")
if country_container[1].text =="China":
continue
for i in range(1, len(country_container)):
final_feature = country_container[i].text
if clean:
if i != 1 and i != len(country_container)-1:
final_feature = final_feature.replace(",","")
if final_feature.find('+') != -1:
final_feature = final_feature.replace("+","")
final_feature = float(final_feature)
elif final_feature.find("-") != -1:
final_feature = final_feature.replace("-","")
final_feature = float(final_feature)*-1
if final_feature == "N/A":
final_feature = 0
elif final_feature == "" or final_feature == " ":
final_feature = -1
country_data.append(final_feature)
all_data.append(country_data)
La Data extraída se transforma en DataFrame para ser procesada. Posteriormente, las columnas son etiquetadas y asignadas a un formato según corresponda.
df = pd.DataFrame(all_data)
df
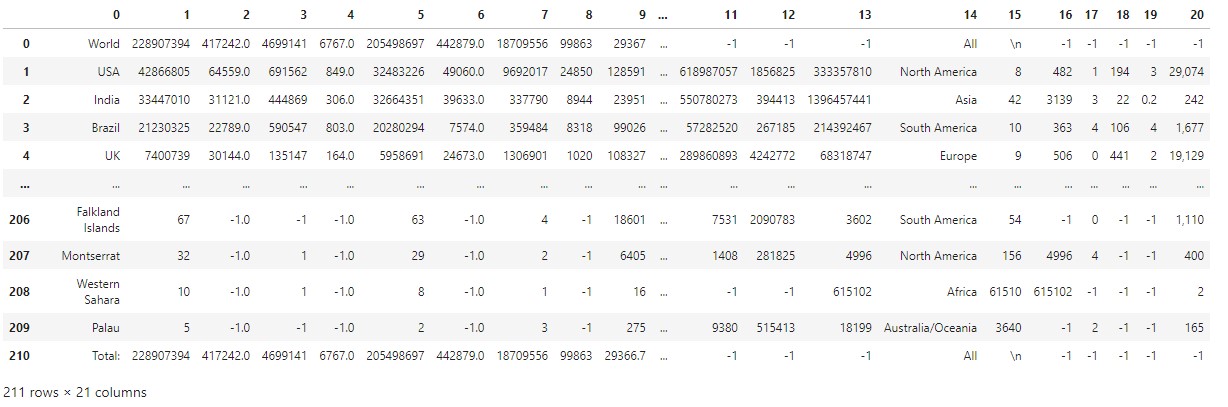
df.drop([15, 16, 17, 18, 19, 20], inplace = True, axis = 1)
column_labels = ["País","Total Casos","Nuevos Casos","Total Muertes","Nuevas Muertes","Total Recuperados","Nuevos Recuperados",
"Casos Activos","Serios/Críticos","Total Casos/1M","Muertes/1M","Total Tests","Tests/1M","Población","Continente"]
df.columns = column_labels
df
for label in df.columns:
if label != 'País' and label != "Continente":
df[label] = pd.to_numeric(df[label])
df
Se crea el all_data_covid-19.csv para almacenar los datos extraídos.
df.to_csv ('all_data_covid-19.csv', index = False, header=True)
Con la Data final almacenada en df ya es posible generar nuevas variables o indicadores según se requiera, para luego realizar el análisis y la exploración gráfica.
A modo de ejemplo, se genera nuevas variables y algunos gráficos; primero de forma agregada, luego por continentes, después se realiza una segmentación por países y finalmente una revisión del los casos de Covid-19 en América del Sur.
df["%Inc Casos"] = df["Nuevos Casos"]/df["Total Casos"]*100
df["%Inc Muertes"] = df["Nuevas Muertes"]/df["Total Muertes"]*100
df["%Inc Recuperados"] = df["Nuevos Recuperados"]/df["Total Recuperados"]*100
df
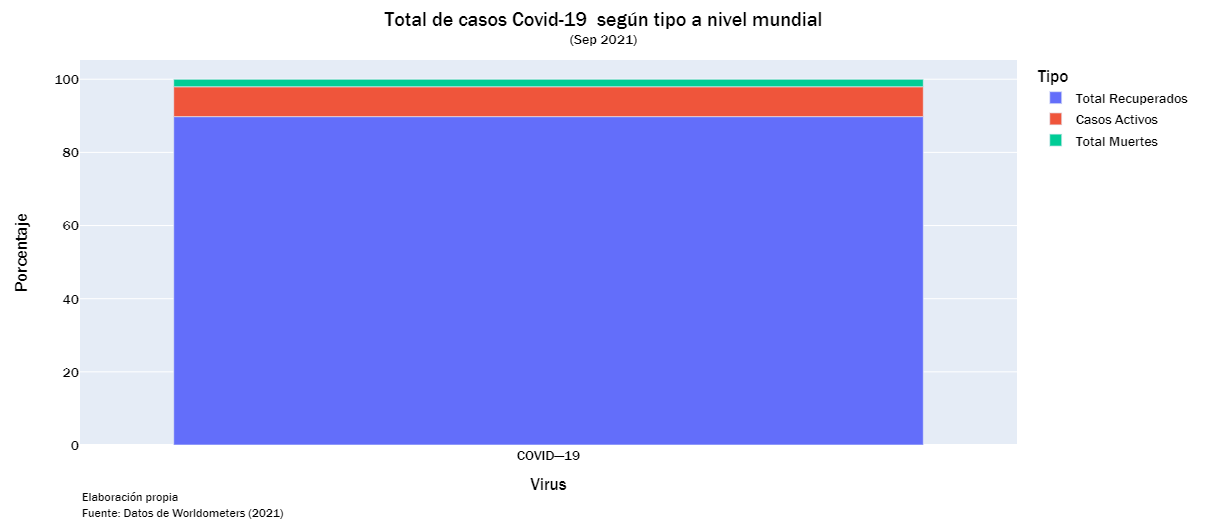
Casos según:
- Total de recuperados
- Total de casos activos
- Total de fallecidos
cases = df[["Total Recuperados","Casos Activos","Total Muertes"]].loc[0]
cases_df = pd.DataFrame(cases).reset_index()
cases_df.columns = ["Tipo","Total"]
cases_df["Porcentaje"] = np.round(100*cases_df['Total']/np.sum(cases_df["Total"]),2)
cases_df["Virus"] = ["COVID—19" for i in range(len(cases_df))]
#print(cases_df)
fig = px.bar(cases_df, x = "Virus", y = "Porcentaje", color = "Tipo", hover_data = ["Total"])
fig.update_layout(title={'text': "Total de casos Covid-19 según tipo a nivel mundial<br><sup>(Sep 2021)</sup>",
'y':0.95,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
font=dict(family="Franklin Gothic",
size = 14,
color="black")
)
note = 'Elaboración propia <br>Fuente: Datos de <a href="https://www.worldometers.info/coronavirus/#countries">Worldometers</a> (2021)'
fig.add_annotation(text=note,
font=dict(size=12),
align="left",
x=0.0,
y=-0.2,
xref="x domain",
yref="y domain",
showarrow=False,
)
fig.show()
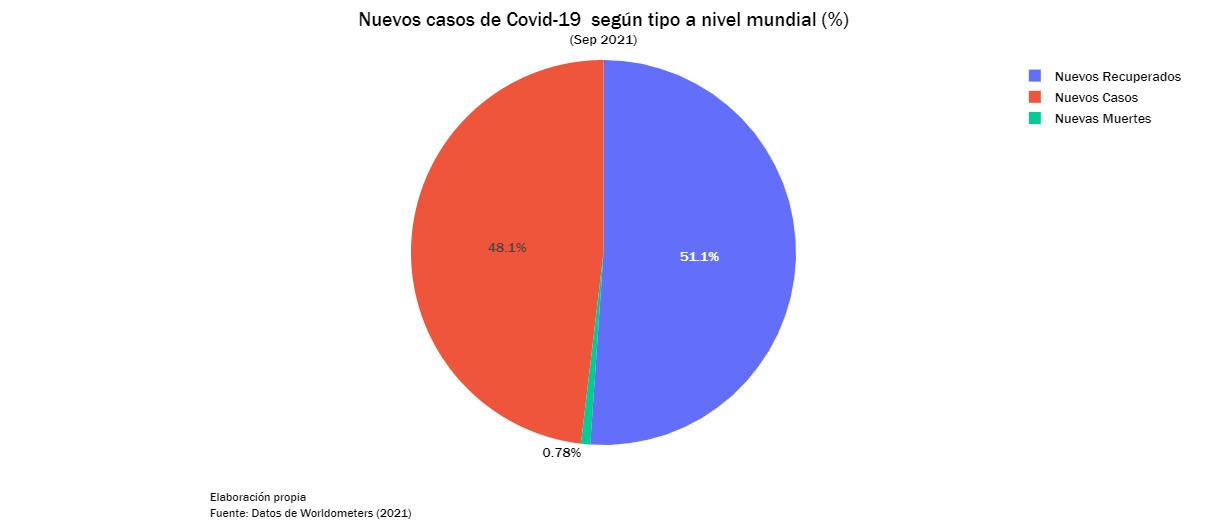
cases = df[["Nuevos Recuperados","Nuevos Casos","Nuevas Muertes"]].loc[0]
cases_df = pd.DataFrame(cases).reset_index()
cases_df.columns = ["Tipo","Total"]
cases_df["Porcentaje"] = np.round(100*cases_df['Total']/np.sum(cases_df["Total"]),2)
cases_df["Virus"] = ["COVID—19" for i in range(len(cases_df))]
#print(cases_df)
fig = px.pie(cases_df, names = "Tipo", values = "Porcentaje", hover_data = ["Total"])
fig.update_layout(title={'text': "Nuevos casos de Covid-19 según tipo a nivel mundial (%)<br><sup>(Sep 2021)</sup>",
'y':0.95,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
font=dict(family="Franklin Gothic",
size = 14,
color="black")
)
note = 'Elaboración propia <br>Fuente: Datos de <a href="https://www.worldometers.info/coronavirus/#countries">Worldometers</a> (2021)'
fig.add_annotation(text=note,
font=dict(size=12),
align="left",
x=0.0,
y=-0.20,
xref="x domain",
yref="y domain",
showarrow=False,
)
fig.show()
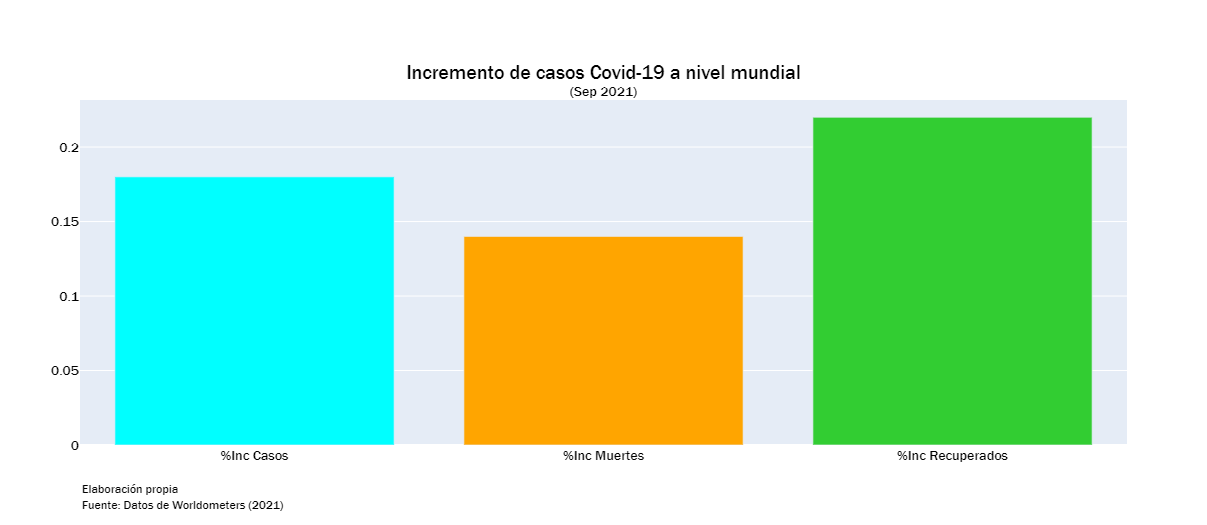
per = np.round(df[["%Inc Casos","%Inc Muertes","%Inc Recuperados"]].loc[0],2)
per_df = pd.DataFrame(per)
per_df.columns = ["Porcentaje"]
fig = go.Figure()
fig.add_trace(go.Bar(x = per_df.index, y = per_df["Porcentaje"], marker_color = ["cyan","orange", "limegreen"]))
fig.update_layout(title={'text': "Incremento de casos Covid-19 a nivel mundial<br><sup>(Sep 2021)</sup>",
'y':0.85,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
font=dict(family="Franklin Gothic",
size = 14,
color="black")
)
note = 'Elaboración propia <br>Fuente: Datos de <a href="https://www.worldometers.info/coronavirus/#countries">Worldometers</a> (2021)'
fig.add_annotation(text=note,
font=dict(size=12),
align="left",
x=0.0,
y=-0.20,
xref="x domain",
yref="y domain",
showarrow=False,
)
fig.show()
continent_df = df.groupby("Continente").sum().drop("All")
continent_df = continent_df.reset_index()
continent_df

note = 'Elaboración propia <br>Fuente: Datos de <a href="https://www.worldometers.info/coronavirus/#countries">Worldometers</a> (2021)'
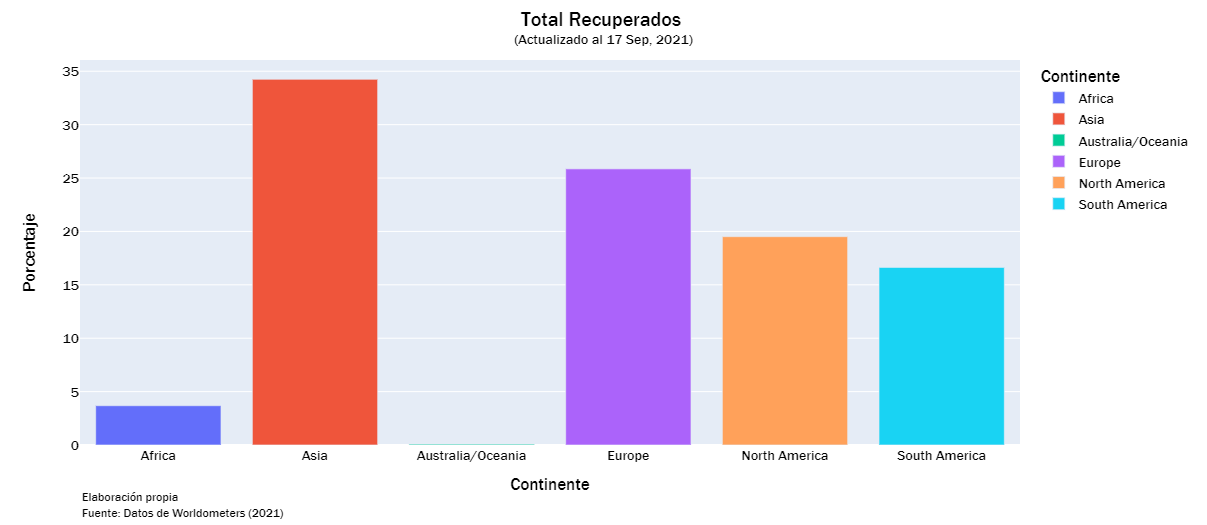
def continent_visualization(vis_list):
for label in vis_list:
c_df = continent_df[['Continente', label]]
c_df["Porcentaje"] = np.round(100*c_df[label]/np.sum(c_df[label]),2)
c_df["Virus"] = ['Covid — 19' for i in range(len(c_df))]
fig = px.bar(c_df,
x= 'Continente',
y= 'Porcentaje',
color= 'Continente',
hover_data=[label])
fig.update_layout(title={'text':f"{label} <br><sup>(Actualizado al {yesterday_str})</sup>",
'y':0.95,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
font=dict(family="Franklin Gothic",
size = 14,
color="black")
)
fig.add_annotation(text=note,
font=dict(size=12),
align="left",
x=0.0,
y=-0.20,
xref="x domain",
yref="y domain",
showarrow=False,
)
fig.show()
gc.collect()
cases_list = ["Total Casos","Casos Activos", "Nuevos Casos", "Serios/Críticos", "Total Casos/1M", "%Inc Casos"]
deaths_list = ["Total Muertes","Nuevas Muertes", "Muertes/1M", "%Inc Muertes"]
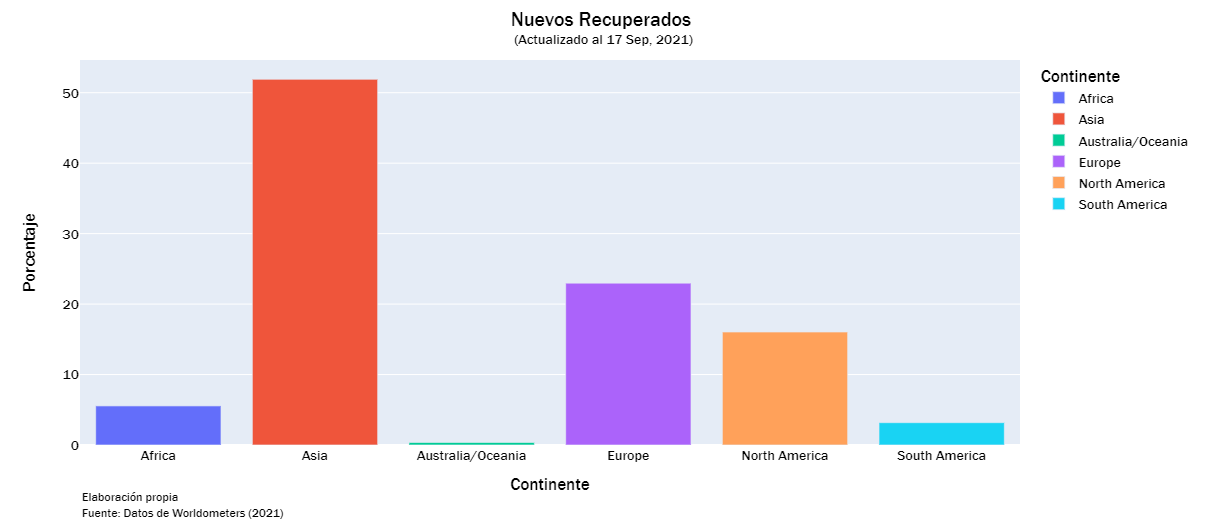
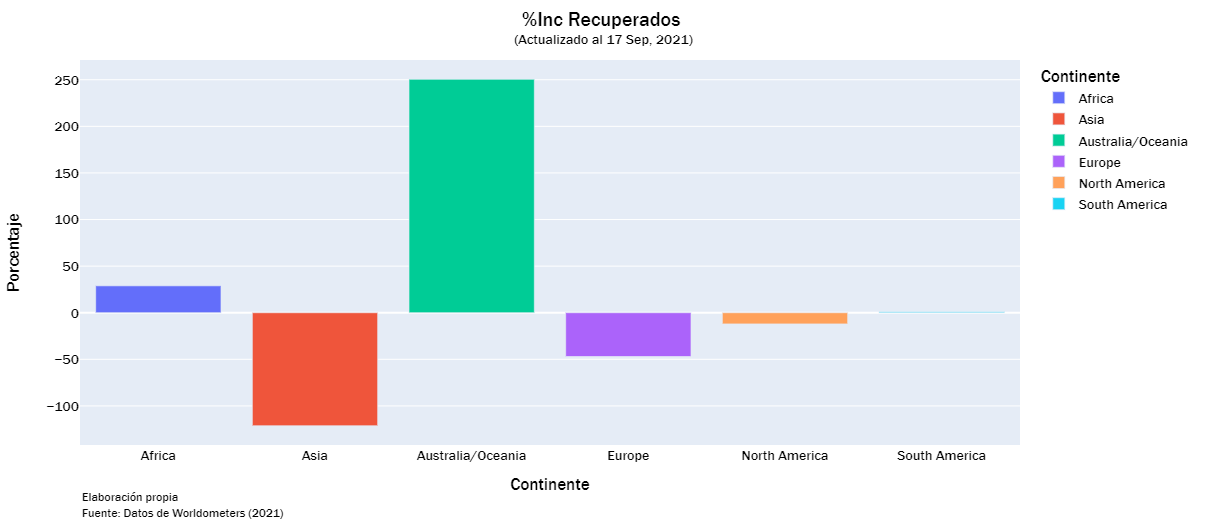
recorvered_list = ["Total Recuperados", "Nuevos Recuperados", "%Inc Recuperados" ]
continent_visualization(cases_list)
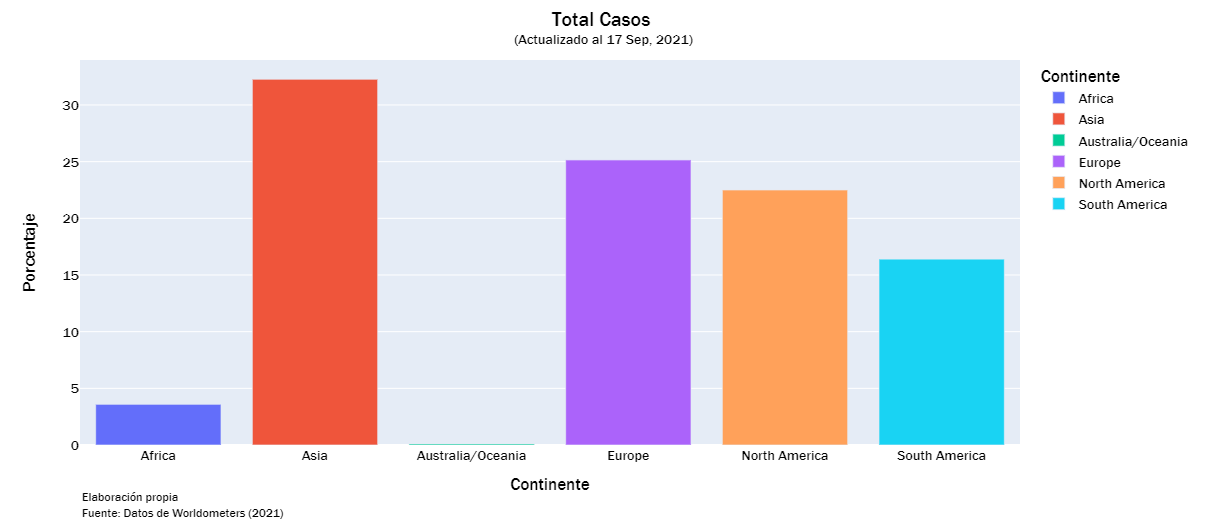
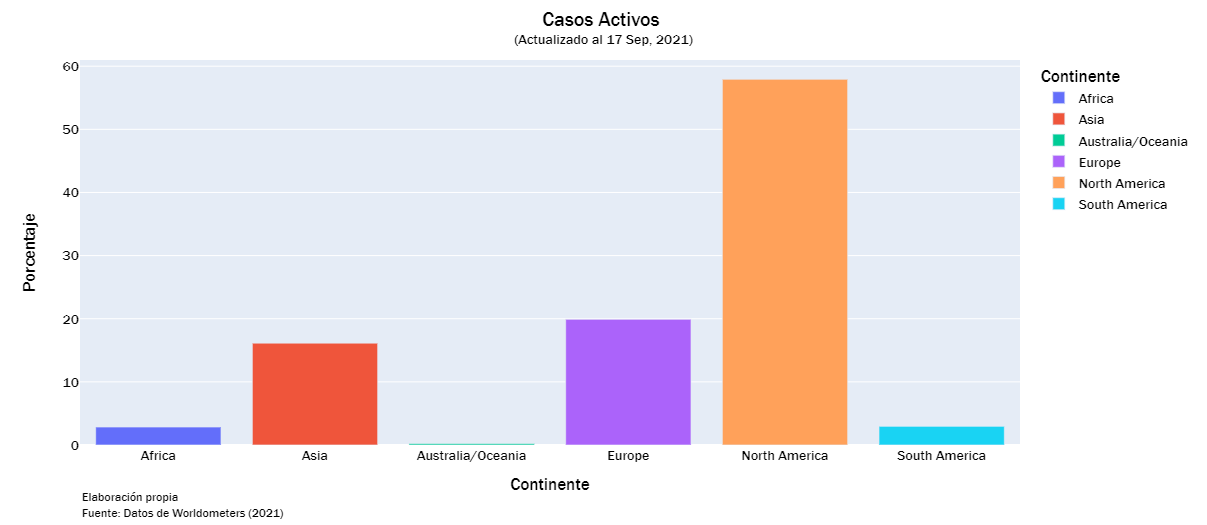
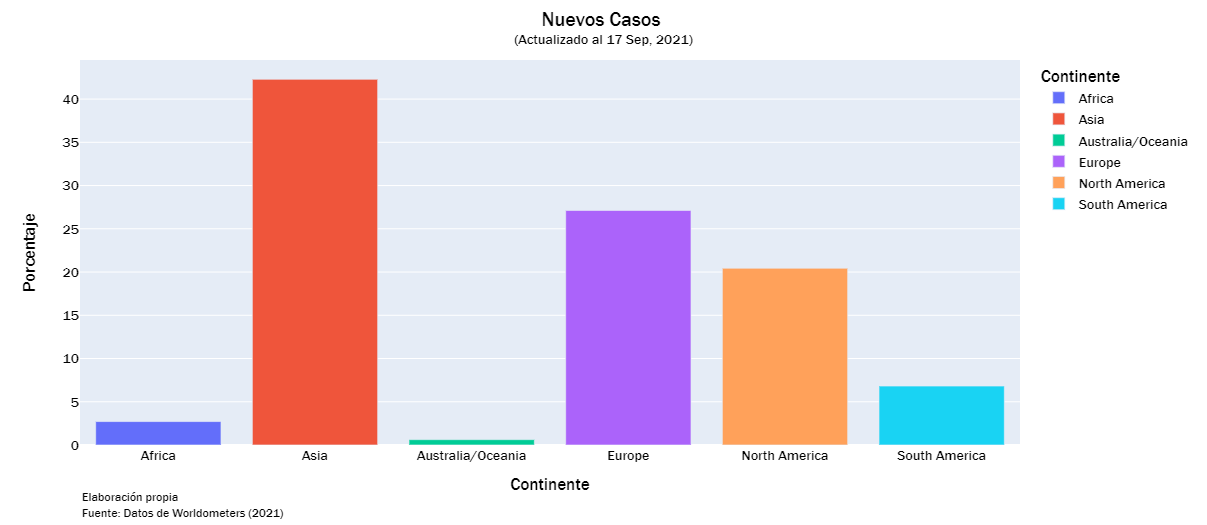
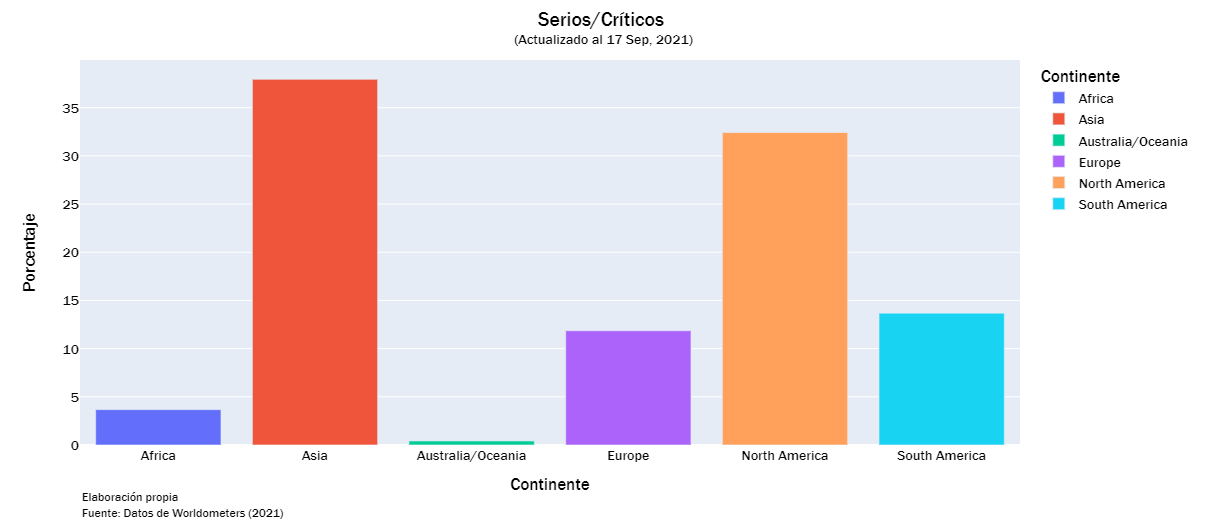
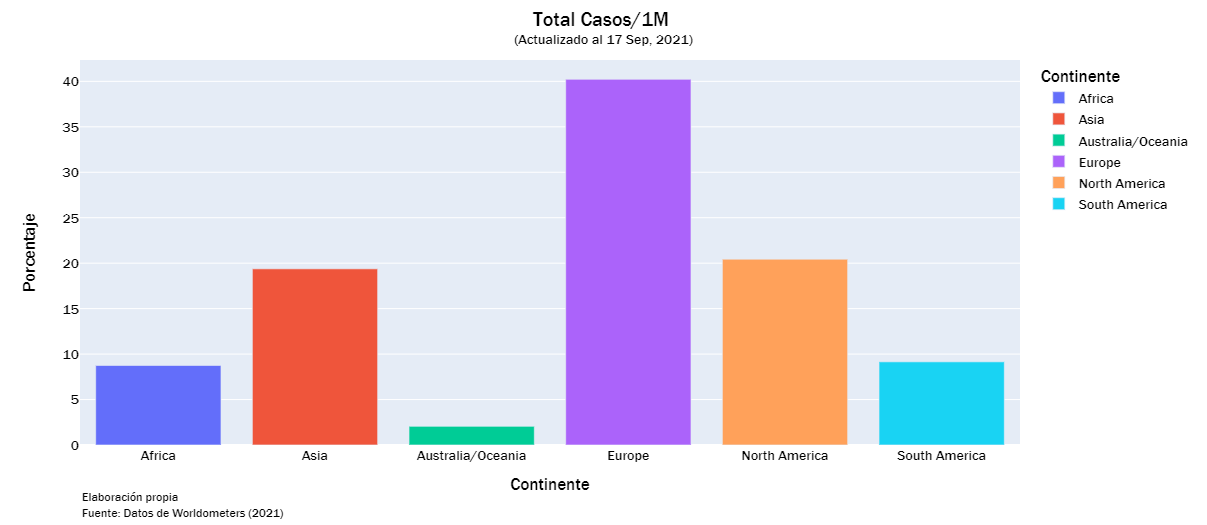
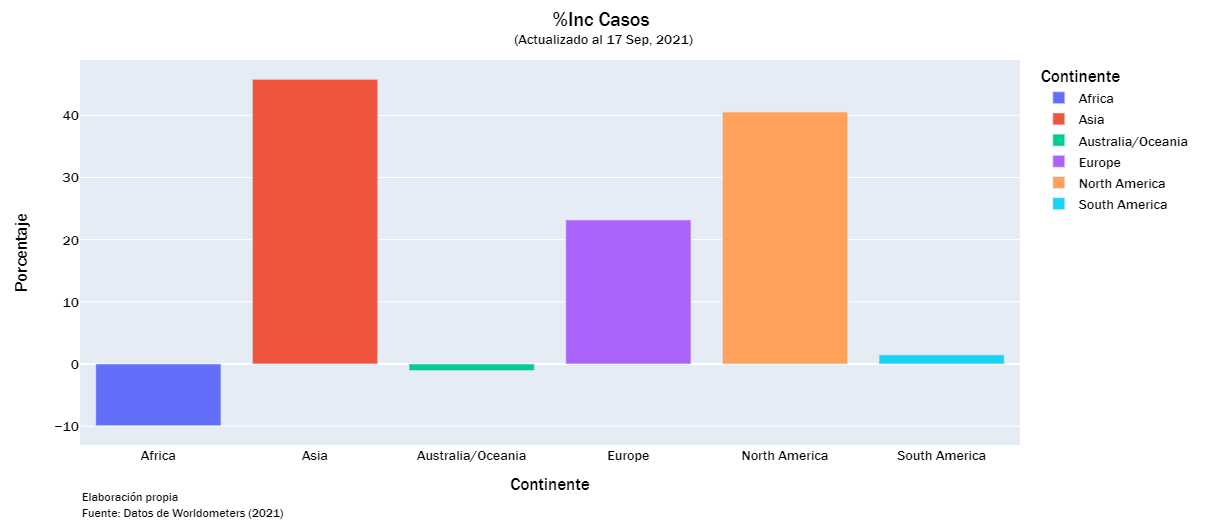
continent_visualization(deaths_list)
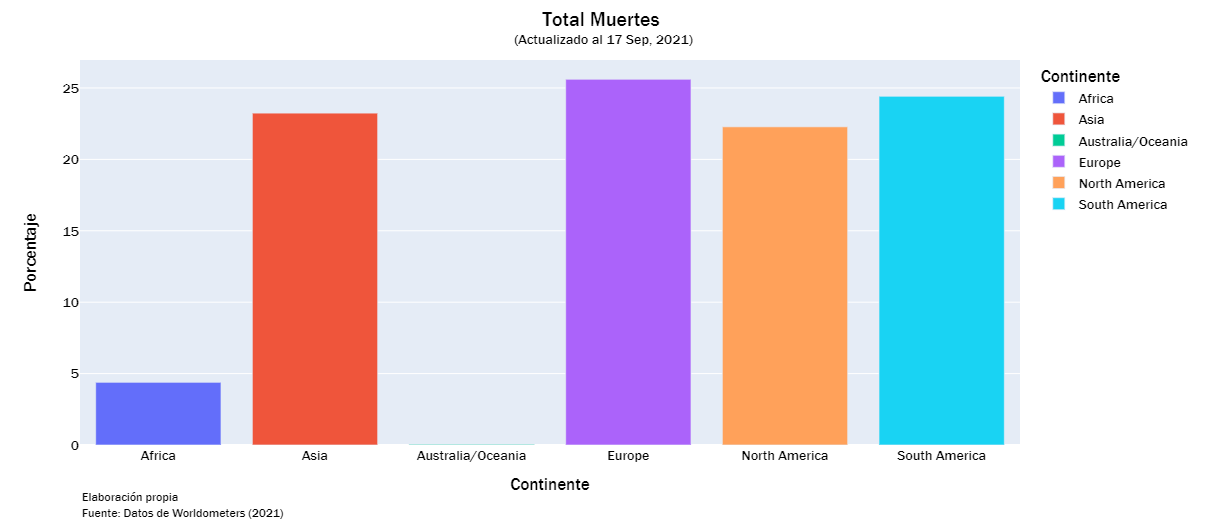
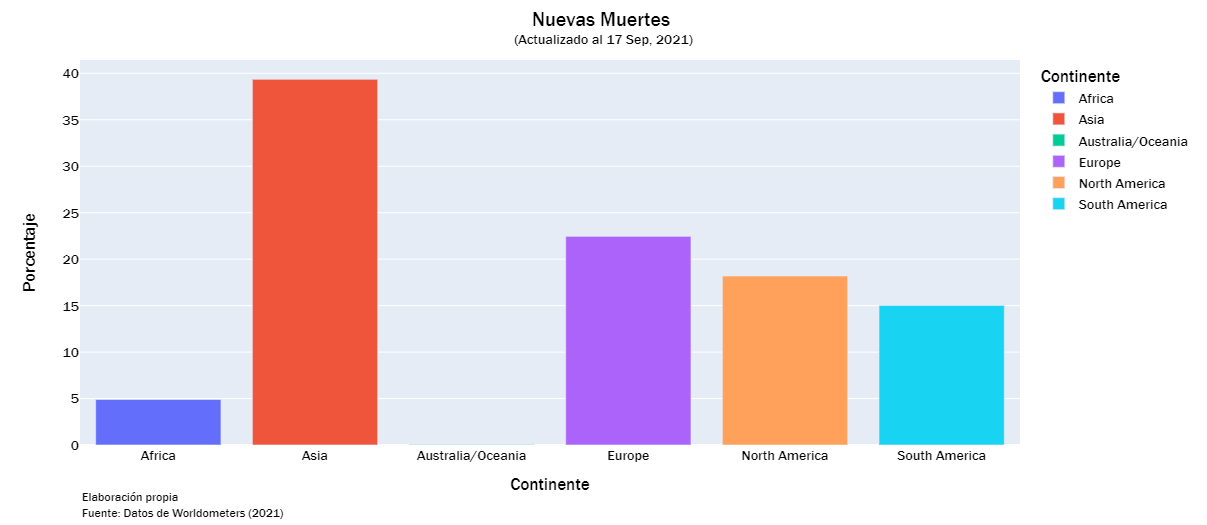
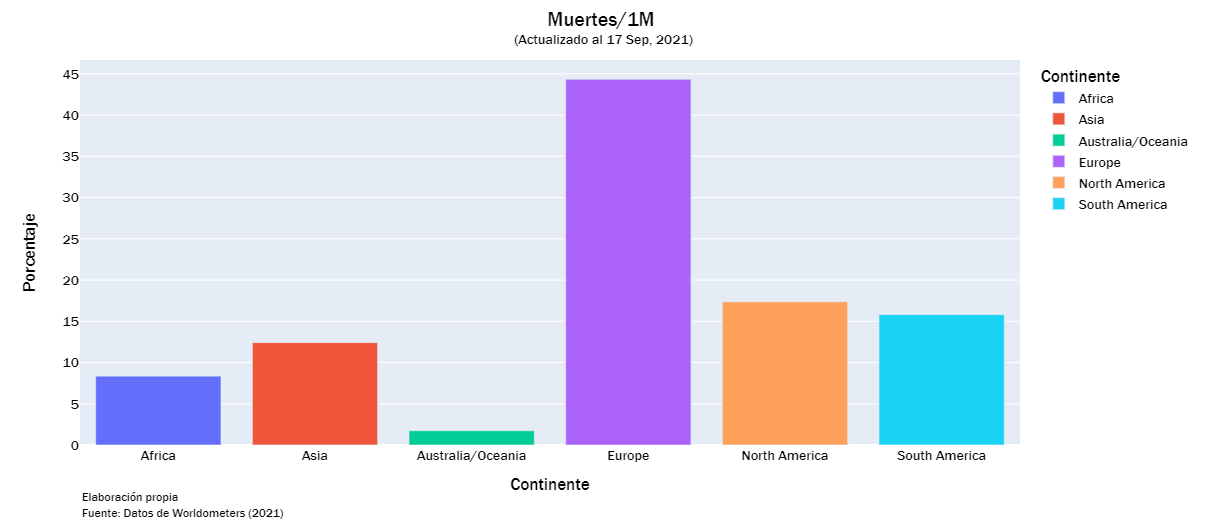
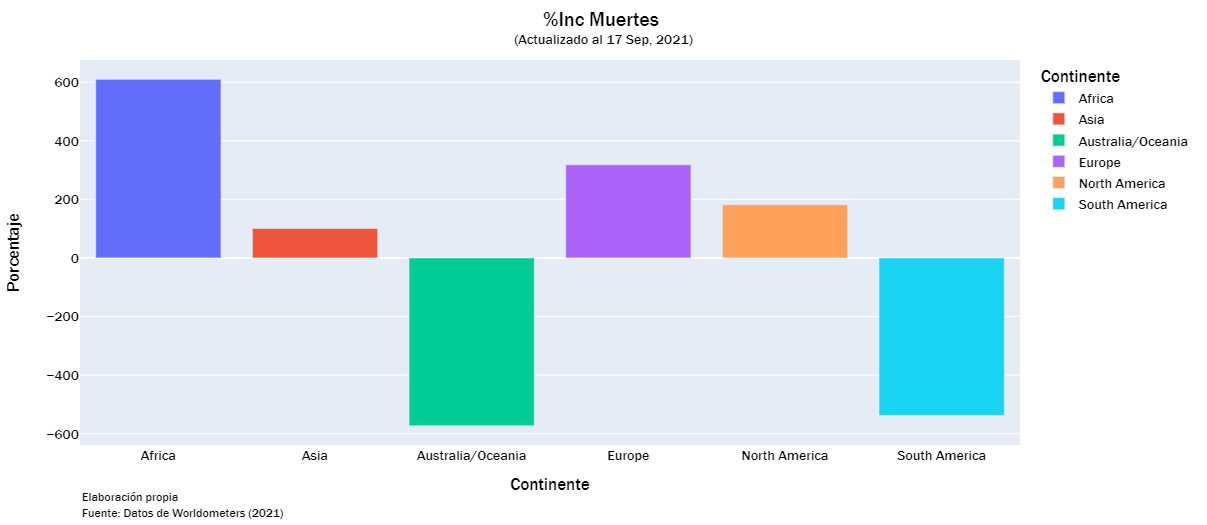
continent_visualization(recorvered_list)
df = df.drop(len(df)-1)
country_df = df.drop([0])
country_df
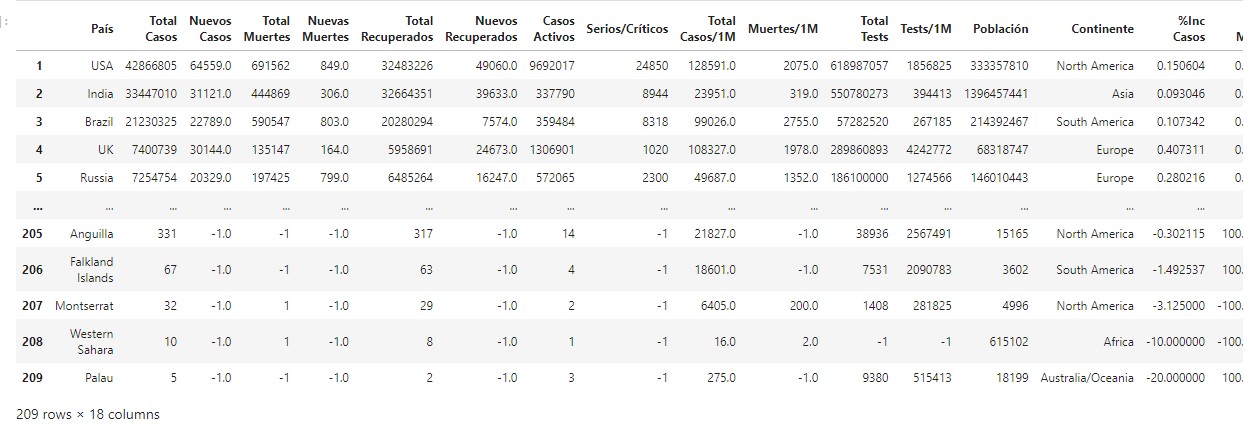
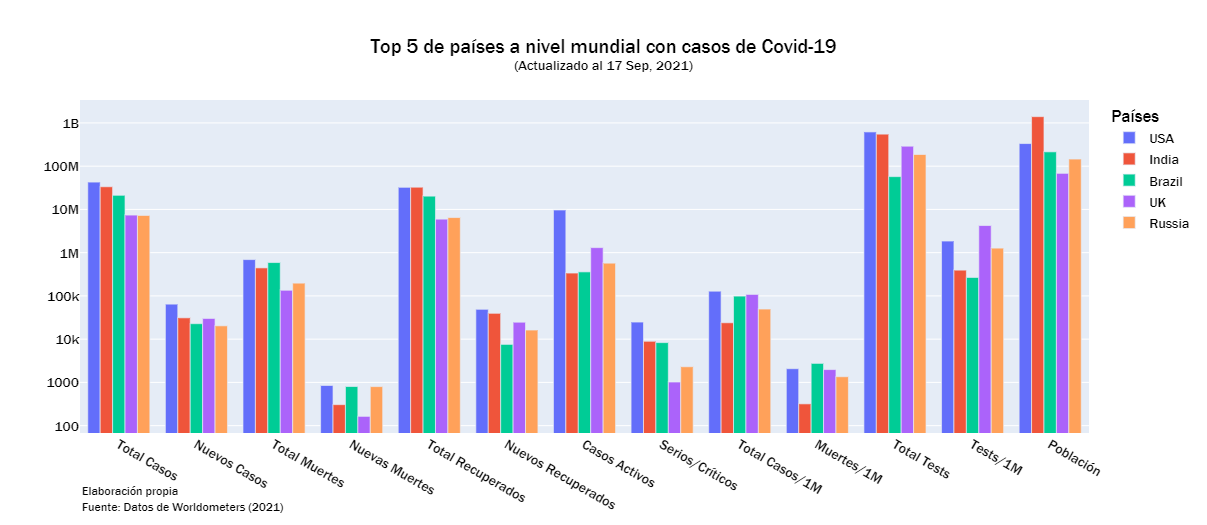
LOOK_AT = 5
country = country_df.columns[1:14]
fig = go.Figure()
c = 0
for i in country_df.index:
if c < LOOK_AT:
fig.add_trace(go.Bar(name= country_df['País'][i], x= country, y= country_df.loc[i][1:14]))
else:
break
c +=1
fig.update_layout(title = {'text':f'Top {LOOK_AT} de países a nivel mundial con casos de Covid-19<br><sup>(Actualizado al {yesterday_str})</sup>',
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top' },
yaxis_type = "log",
legend_title="Países",
font=dict(family="Franklin Gothic",
size = 14,
color="black")
)
note = 'Elaboración propia <br>Fuente: Datos de <a href="https://www.worldometers.info/coronavirus/#countries">Worldometers</a> (2021)'
fig.add_annotation(text=note,
font=dict(size=12),
align="left",
x=0.0,
y=-0.25,
xref="x domain",
yref="y domain",
showarrow=False,
)
fig.show()
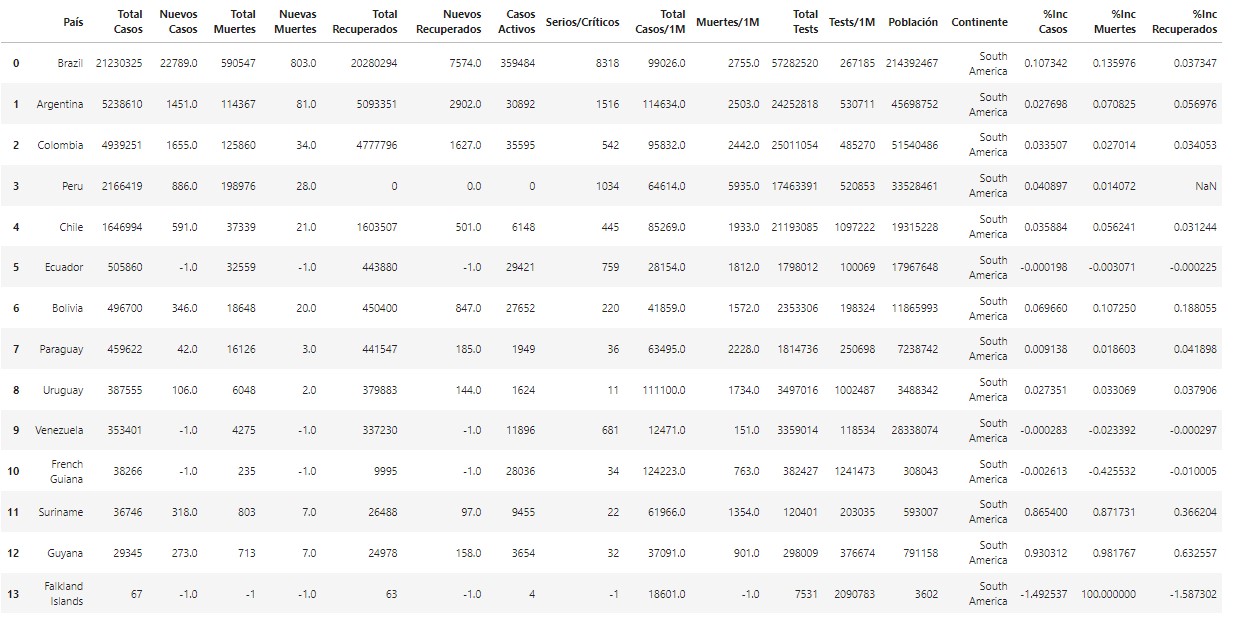
south_df = country_df.loc[country_df["Continente"] == "South America"].reset_index()
south_df = south_df.drop(columns=["index"])
south_df
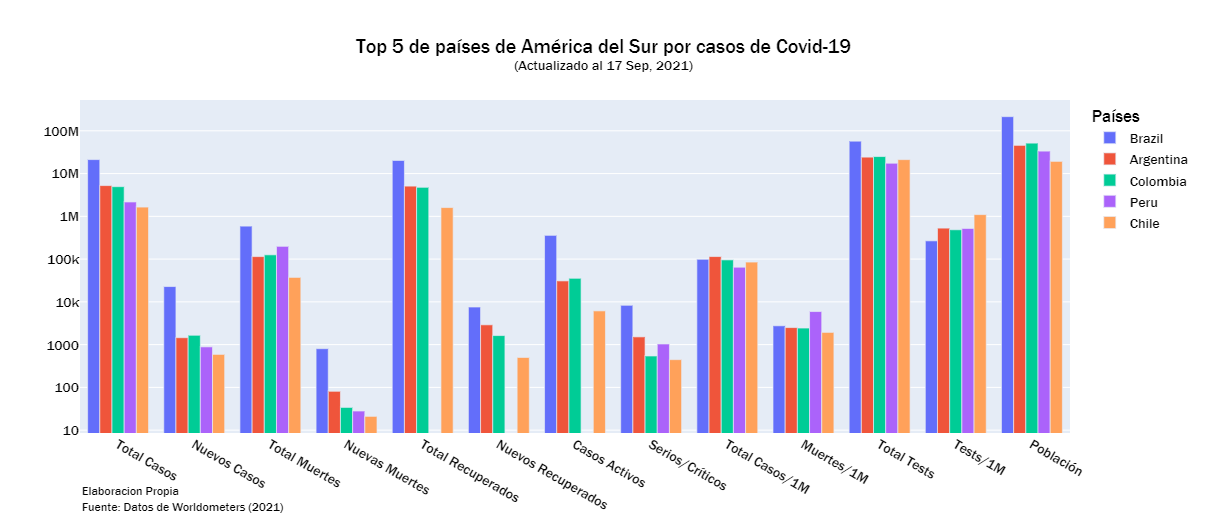
LOOK_AT = 5
south = south_df.columns[1:14]
fig = go.Figure()
c = 0
for i in south_df.index:
if c < LOOK_AT:
fig.add_trace(go.Bar(name= south_df['País'][i], x= country, y= south_df.loc[i][1:14]))
else:
break
c +=1
fig.update_layout(title = {'text':f'Top {LOOK_AT} de países de América del Sur por casos de Covid-19<br><sup>(Actualizado al {yesterday_str})</sup>',
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top' },
yaxis_type = "log",
legend_title="Países",
font=dict(family="Franklin Gothic",
size = 14,
color="black")
)
note = 'Elaboracion Propia <br>Fuente: Datos de <a href="https://www.worldometers.info/coronavirus/#countries">Worldometers</a> (2021)'
fig.add_annotation(text=note,
font=dict(size=12),
align="left",
x=0.0,
y=-0.25,
xref="x domain",
yref="y domain",
showarrow=False,
)
fig.show()
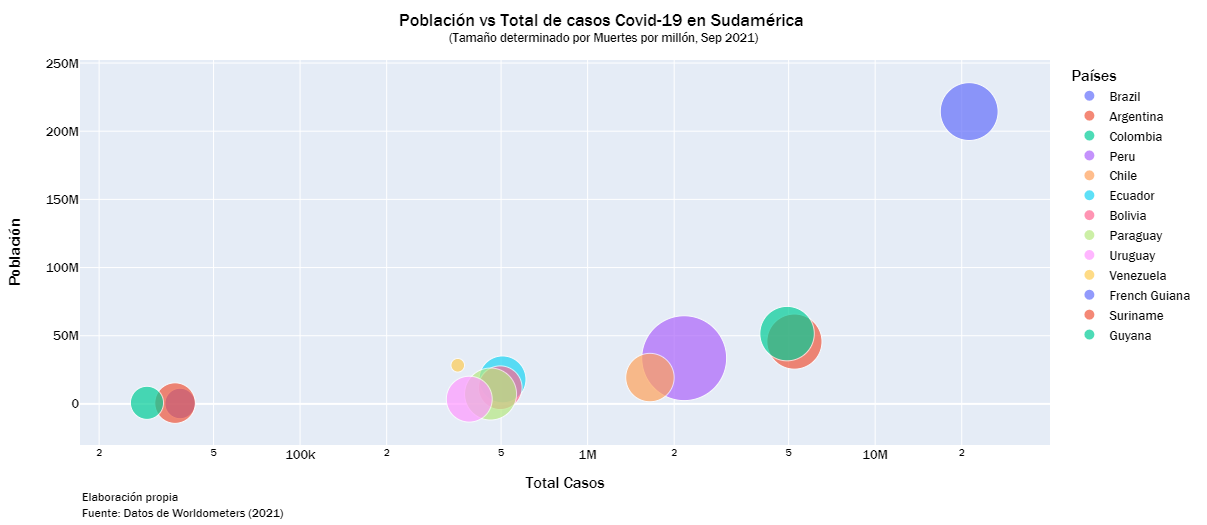
south_df1 = south_df.loc[south_df["Muertes/1M"] > 0]
fig = px.scatter(south_df1, x="Total Casos", y="Población",
size="Muertes/1M", color="País",
hover_name="País", log_x=True, size_max=60)
fig.update_layout(
title={
'text': "Población vs Total de casos Covid-19 en Sudamérica <br><sup>(Tamaño determinado por Muertes por millón, Sep 2021)</sup> ",
'y':0.95,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
legend_title="Países",
font=dict(family="Franklin Gothic",
size = 13,
color="black")
)
note = 'Elaboración propia <br>Fuente: Datos de <a href="https://www.worldometers.info/coronavirus/#countries">Worldometers</a> (2021)'
fig.add_annotation(text=note,
font=dict(size=12),
align="left",
x=0.0,
y=-0.2,
xref="x domain",
yref="y domain",
showarrow=False,
)
fig.show()