This is a repo that represents our classwork and some notes on the bellman equation. Feel free to use this as you see fit.
Formally the bellman equation is
- s := our state
- a := our action
- V := is the optimal value function. It is a magical function that always find the maximum value in the long run. If it makes you happy you can represent it as
$V_{max}$ -
$s'$ := our new state that is reached when we perform action$a$ on state$s$ . We can think of$s' = T(s,a)$ where$T$ is our transition function. - R(s,a) := immediate reward function. Also known as Immediate Value Function. This will vary problem to problem.
In english, we can calculate the maximum value for the entire problem starting at state
Our V function is going to be the sum of our current/immediate reward function and our projected future rewards.
Our future rewards is represented by
You will notice that this equation is recursive and will go on forever if we let it because there will always be a new state. We must define some
In class we discussed the concept of runtime complexity. In essence, runtime complexity is how much longer your program will take to finish as we make it bigger. If your problem is 3 times as big now, by what factor will your runtime grow?
Here is a pretty good link that explains the concept of big O. You won't have to use this ever, but its good to know
Formal definition of Big O
If we look at the math behind this statement, it means we can always pick out sufficiently large values for and n so that f serves as an upper bound of g.
This is similar to the concept of limits that you may have encountered in calculus. Just like limits, you can pretty much just look at the "biggest" term and pay attention to that.
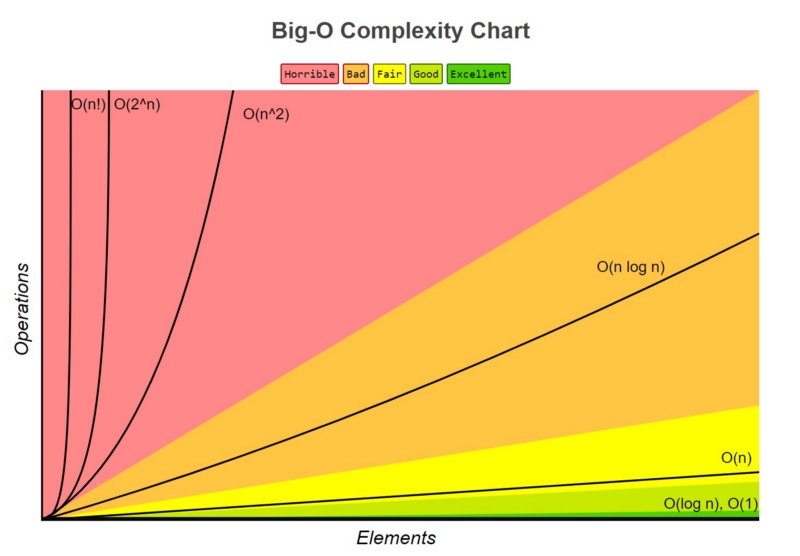
This means that f(x) serves as a conceptual upper bound for g(x). Rather than talking about some very specific functions we can very easily communicate just about how fast (or slow) our program will be.
| Big O | Example |
|---|---|
| O(1) | normal operations (=, +, -, *,/,**) |
| O(log(n)) | searchign for things when they've been organized in groups |
| O(n) | for loops |
| O(nlog(n)) | organizing things into groups and then searching for an item |
| O(n^2) | double nested for loops |
| O(n^3) | triple nested for loops |
| O(n^4) | quad nested for loops |
| O(2^n) | Branching operations. Usually recursive or forking calls |
| O(n!) | More complex combinatorial checks |
Most problems that we will be interested in this class will be
In the knapsack problem we pretend like we are a robber. We sneak into the castle and have a choice to steal or not to steal. The caveat is that we have a limited amount of space in our knapsack. How do we pick the best combination of items?
Lets take a look at our information
| Item Idx | Weight | Value |
|---|---|---|
| 0 | ||
| 1 | ||
| 2 | ||
| 3 | ||
| ... | ... | ... |
| n |
Lets define
Our objective becomes
with respect to our constraint of maximum weight
Our action space is as defined above. Every single item we can either take or not take. 0 or 1 for every state. Easy peasy. Sometimes we will have different action spaces dependent on our current state
Our state space is more nuanced. Remember state functions don't care about the past. They only care abou thte present and in Dynamic Programming we care about the future. So our state space should capture some of this information.
Our state should also give us information about the subproblem. We need this to have our nice little recursive relationship. These can be pretty tricky to define, but once you get the hang of it, there's no stopping you.
In our case we care about what item index we are currently making a decision about and how much weight is remaining from our maximum. If we are at item 4 with a remaining weight of 20 our future value will not affected by our decisions for items 0-3 (though our cummulative value will be.)
What happens when we add an item to our bag? Well our bag gets heavier and closer to our carrying capacity. That means we have less remaining weight in our bag. We have also made a decision about our current item, so it's time to move on to our next item.
What happens when we decide not to add an item? Well our carrying capacity is unaffected, but we shouldn't make two decisions on that item so we should move onto the next one.
Our reward function is the amount that our cumulative total increases as a result of our action.
How much does our total reward
The answer is
When are we done with the problem? We have two cases right?
- We are out of weight
- We are out of items in either case there is no need to update our state and keep going with these recursive calls. Our value for all future periods will be 0.
This is all the information we need to implement.