{kind=link}
GAN requires lots of training data, so we want to design a novel architecture that could help training data generation. Specifically, Chinese characters are used in this investigation. That is, we try to use limited training data to capture the writing style of user. The model could learn right now, however, requires 20% of target characters. For instance, if 10000 samples are desired so 2000 training set should be fed into the nets.
The whole architecture looks like
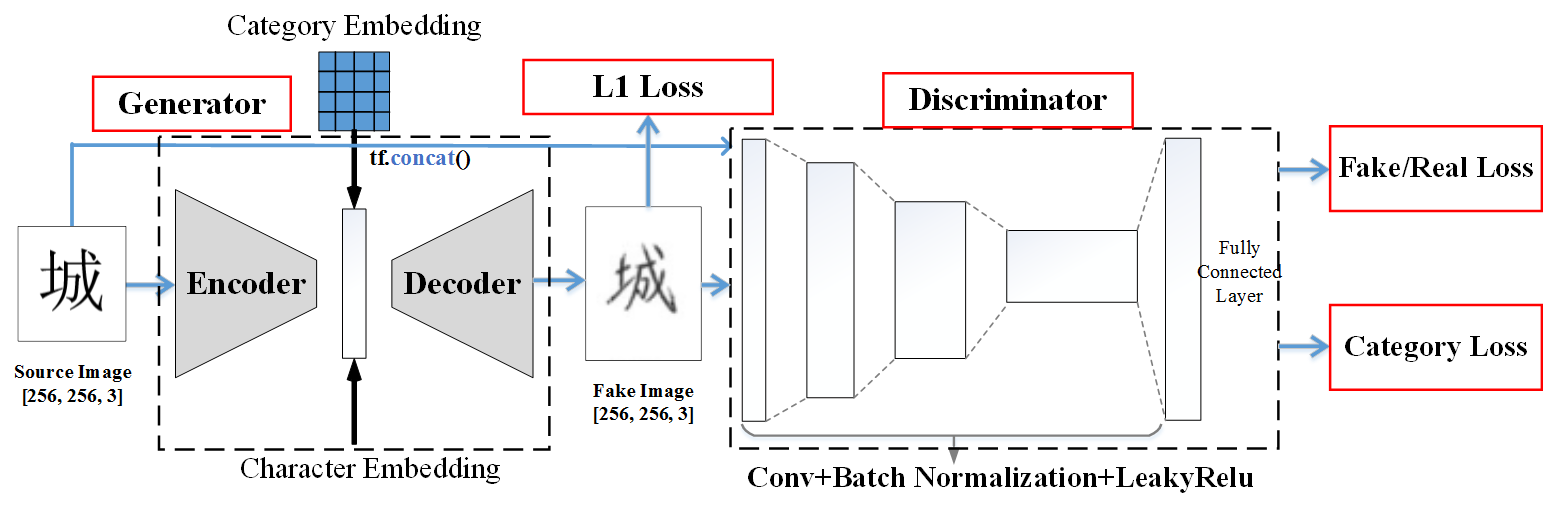 and for the encoder part
and for the encoder part


This is my final year project in Pattern Recognition & Machine Intelligence Laboratory. PremiLab is a new lab set up by the dean of EEE department, XJTLU.