Background / Purpose / Getting Started / Cluster Guide

We live in a digital world full of data. Whether that is un-, semi- or structured data, there is a lot of things we can do with it if we make use of Machine Learning (ML). More specifically, supervised, unsupervised or reinforcement learning algorithms are used to build models that learn (train) and discover patterns from historical data to predict an outcome. There are numerous applications of ML such as weather forecast (prediction), storm tracking models, among others.
- Hadoop is a software framework for distributed storage and processing of large data sets across of clusters of computers using MapReduce.
- MapReduce is a programming technique for distributed computing that process vast amounts of data (multi-terabyte data sets) in-parallel on large clusters in a reliable, fault-tolerant manner. MapReduce explained.
- Spark is a a unified analytics engine for large-scale data processing.
Yes. It all sounds the same, let the following image sink in...
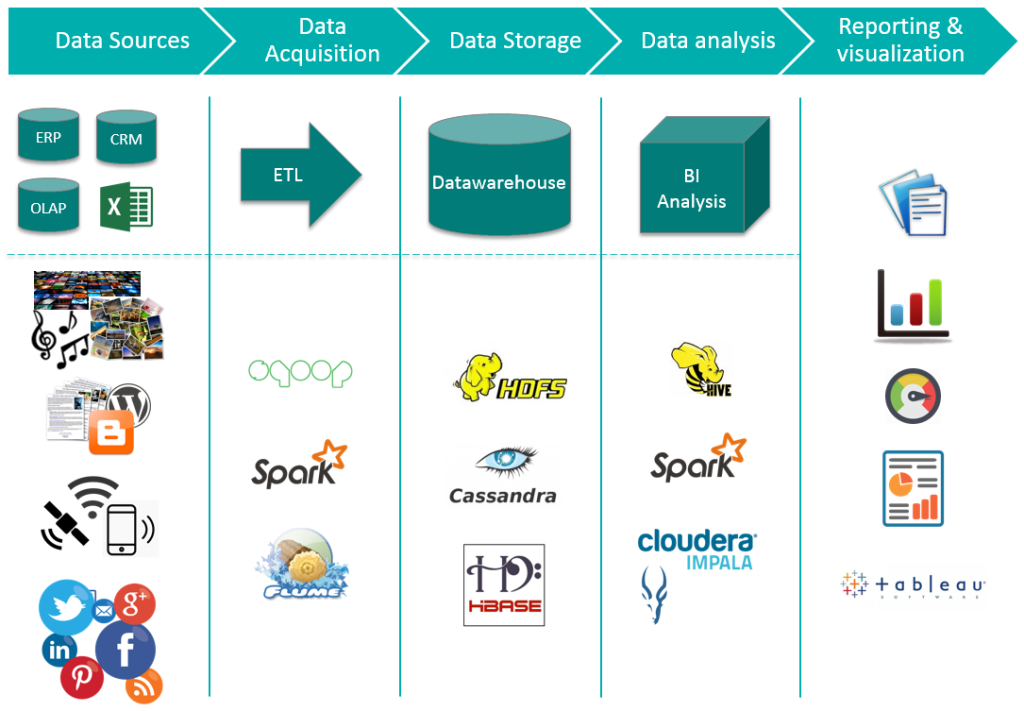
The intention of the cluster is to provide to you with the option of being able to Extract, Transform and Load (ETL) data with Spark while using Hadoop's File System (HDFS) for storaging needs. Data Analysis and Visualization is out this scope and up to your choice.