Coursework and projects from the WPI computer science class CS3013 - Operating Systems.
The goal of Project 1 is to introduce students to the process manipulation facilities in the Linux Operating System. For the project I wrote a C program called doit, that takes another command as an argument and executes that command. For example, executing:
% ./doit wc foo.txt
would invoke the wc ("word count") command with an argument of foo.txt, which will output the number of lines, words, and bytes in the file "foo.txt." After execution of the specified command has completed, doit displays statistics that show some of the system resources the comman used. In particular it shows:
- the amount of CPU time used (both user and system time (in milliseconds),
- the elapsed "wall-clock" time for the command to execute (in milliseconds),
- the number of times the process was preempted involuntarily (e.g. the time slice expired, preemption by higher priority process),
- the number of times the process gave up the CPU voluntarily (e.g. waiting for a resource),
- the number of major page faults, which require disk I/O,
- the number of minor page faults, which could be satisfied by reclaiming memory,
- the maximum resident set size used, which is given in kilobytes.
doit also has the ability to act as a shell. Calling doit with no command line arguments will
engage shell mode, and prompt the user with the default prompt string of ==>. You can enter
comands into this shell just as you would with a regular Linux shell, with the exception that the
doit shell will also print the same usage statistics for every command executed on it.
Shell mode has four built-in commands. These are:
- exit - causes the shell to terminate.
- cd dir - changes the directory to dir.
- set prompt = newprompt - changes the prompt to newprompt.
- jobs - lists all background tasks
Each line of input may not contain no more than 128 characters or more than 32 distinct arguments.
Shell mode also supports background tasks, indicated by putting an ampersand ('&') character at the end of an input line. When a task runs in the background the shell does not wait for the task to complete, but instead immediately prompts the user for another command. Note that any output from the background command will intermingle with output from the shell and other commands.
The goal of Project 2 is to learn how to use Loadable Kernel Modules (LKMs) to change the operation of the base operating system arbitrarily. In Pre-Project 2 we compiled a modified version of the Linux Kernel with three new system calls:
cs3013_syscall1cs3013_syscall2cs3013_syscall3
In project 2, I wrote a C program, mymodule.c that intercepts several system calls and replaces them with new system calls. In particular, it does the following:
- Intercepts the
sys_opencall, replacing it with a modified function that prints something like "User 1000 is opening the file: /etc/motd" when it is called by a normal user, then calls the oldsys_open. - Intercepts the
sys_closecall, replacing it with a modified function that prints something like "User 1000 is closing file descriptor: 2" when it is called by a normal user, then calls the oldsys_close. - Intercepts the
cs3013_syscall2call, which originally did nothing, and replaces it with a new custom function (detailed below).
The new cs3013_syscall2 takes the following form:
long cs3013_syscall2(struct processinfo *info);
where *info is a pointer to a data structure in user space where the system call will put
information about the process. It returns 0 if successful or an error indication if not successful.
The processinfo struct is defined as follows:
struct processinfo {
long state; // current state of process
pid_t pid; // process ID of this process
pid_t parent_pid; // process ID of parent
pid_t youngest_child; // process ID of youngest child
pid_t younger_sibling; // pid of the next younger sibling
pid_t older_sibling; // pid of next older sibling
uid_t uid; // used ID of process owner
long long start_time; // process start time in nanoseconds since boot time
long long user_time; // CPU time in user mode (microseconds)
long long sys_time; // CPU time in system mode (microseconds)
long long cutime; // user time of children (microseconds)
long long cstime; // system time of children (microseconds)
}; // struct processinfotest.c is a simple C program to test the system call modifications. After compiling the Loadable
Kernel Module from mymodule.c and the test executable from test.c with the make command, insert
it into the kernel using:
sudo insmod mymodule.ko
Then compile the test program with:
gcc test.c -o test
and run it with ./test. It should call the modified cs3013_syscall2 and print out all the
information stored in a new user-level struct processinfo.
The goal of Project 3 is to learn how to use semaphores and threads as a synchronization mechanism to build a
message passing mechanism that can be used among a set of threads within the same process. The project uses
the pthreads library for thread and synchronization routines.
The project can be compiled with the make command. This creates two executables named addem and life.
Part 1 of the project is a trivial program that really serves to introduce the concepts of threads and semaphores. This program is adds up all the positive integers below an input number, and prints the result to the terminal. Call the program with the command:
% ./addem numThreads number
where numThreads is the number of threads you want the program to use, and number is the target number. If
numThreads is greater than the maximum number of threads (10) then that maximum will be used instead.
The program is more than a trivial loop because it is multithreaded. It initializes a number of threads equal to the
given inputThreads argument, along with a "mailbox" for each, consisting of a message pointer and two semaphores.
With these semaphores the mailbox can act like a shared buffer of size 1. The parent thread divides up the work
of the program among each of the child threads, passing them each a message with a range of values to add up. When
the child threads are done adding they pass a new message with the total back to the parent, and the parent adds up
each of these totals for the final result.
Part 2 is a more interesting program - a distributed version of John Conway's Game of Life. Like Part 1, this program is also multithreaded. It uses the same mailbox message passing system as the first part. The parent thread divides up the work of calculating a new game board for each of the children, passing them a message with a range of rows that thread should play the game for. The children send an ALLDONE message back to the parent when they have finished, and the parent synchronizes these results before moving on to the next generation and repeating the process.
To run the program, use the command:
% ./life numThreads, filename, generations, [print] [pause]
where numThreads is the number of threads you want to use, filename is the name of a text file with the starting
pattern to be used, generations is the maximum number of iterations to play, and print and pause are optional
y or n arguments indicating whether the program should print the board after each step and whether it should
pause to wait for user input after each step respectively.
The purpose of this project is to compare the performance of standard file I/O
using the read() system call for input with memory-mapped I/O where the
mmap() system call allows the contents of a file to be mapped to memory.
The memory-mapped portion of the project is also extended to parallelize the processing of memory amongst multiple threads.
The program, proj4, is similar to the GNU strings command, but instead of
finding all printable strings greater than three characters proj4 searches
through a file byte by byte for a specific input string. It then prints the
number of times that string appears in the given file.
To compile the project, simply use the make command. By default make also
compiles doit, the program from Project 1 used to test proj4 (see below). If
you don't want this, just use make proj4.
To run the program, use the command:
./proj4 srcfile searchstring [size | mmap [pn]]
where srcfile is the input file, and searchstring is the string you want to
find. The third argument tells the program whether to use read or mmap mode
(without it proj4 will default to read mode with a chunk size of 1024). If the
third argument is a number the program will enter read mode with the input
number as the chunk size (to a maximum of 8192). If the third argument is the
string literal "mmap" the program will use mmap mode. In mmap mode, an optional
fourth argument of the form p4 will tell the program to use four threads. The
maximum number of threads is 16.
I tested the program with various input files to examine how the different modes performed. All tests were performed on an Intel i5 6200U quad-core processor running Fedora Linux, and searching for the string "a" in the input file. The test files were:
- The full text of the 2009 Affordable Health Care for America Act (2,807,571 bytes)
- The full text of Moby Dick by Herman Melville (1,276,201 bytes)
- The grep command-line utility executable (166,328 bytes)
- The lyrics to “All Star” by Smash Mouth (2014 bytes)
- The full text of the Gettysburg Address. (1511 bytes)
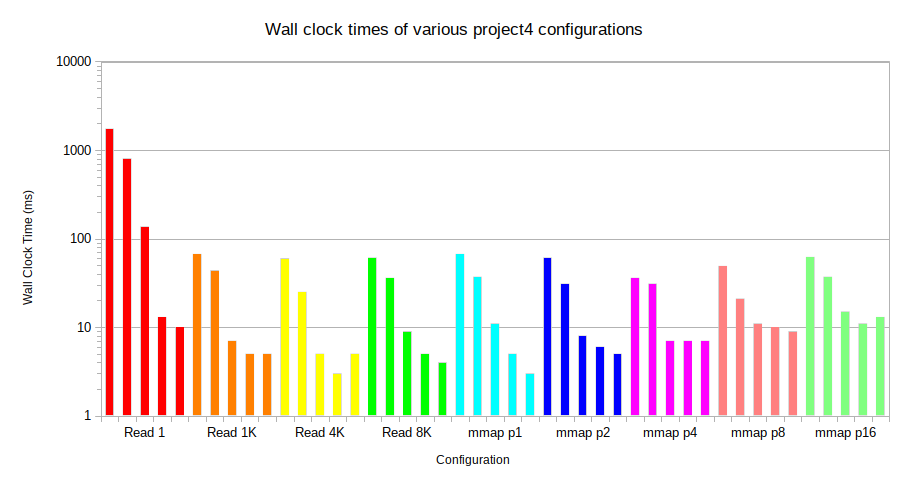
The graph below shows the wall clock execution times for nine different configurations (read mode with chunk sizes of 1, 1024, 4096, and 8192 bytes; and mmap mode with 1, 2, 4, 8, and 16 threads) on each of the input files. Please note that the Y-axis is on a logarithmic scale.
Note: my operating system did not report any page faults during testing, so this report only focuses on wall clock time.
Read mode with a chunk size of 1 has by far the worst performance, taking over one second to execute the longest file. Higher chunk sizes seem to improve the performance, but have diminishing returns on small files.
In mmap mode with only one thread, the wall clock time is already comparable to the 8192-byte chunk size read mode results. Increasing the number of threads increases performance on large files, but actually decreases performance on smaller file sizes. This is likely due to the overhead of managing threads.
It seems that neither method is better in general, but multithreaded memory mapping is faster for large file sizes and small chunk sizes for read mode leads to worse performance.