In this project, I've initially performed EDA steps to explore and clean the data. Then I've build a model that predicts salaries based on various parameters like industry, yearsExperience, Degree, etc.
For the exploratory analysis I first checked for duplicate or missing values, then I merged the test and training data into a sigle data frame. I performed outlier analysis to remove potential outliers. Finally I found that below variable have good correlation with salary:
- jobType
- degree
- industry
- major
- yearsExperience
- milesFromMetropolis
I ran 4 model LinearRegression, make_pipeline(which basically standardizes the data, applies PCA and the Linear regresssion on entire data), RandomForestRegressor and GradientBoostingRegressor. Finally I used Mean Squared Errors are performace evaluation criteria for all the models. Below is an overall summary of all the models.
| Algorithm | MSE |
|---|---|
| Pipeline | 384.48 |
| LinearRegression | 384.47 |
| RandomForestRegressor | 367.93 |
| GradientBoostingRegressor | 357.43 |
From the MSE values, I concluded that GB model has the best prediction accuracy, hence I used this algorithm to predict salaries in train dataset.
Finally, I created a barplot to show importance of each feature
Markup : 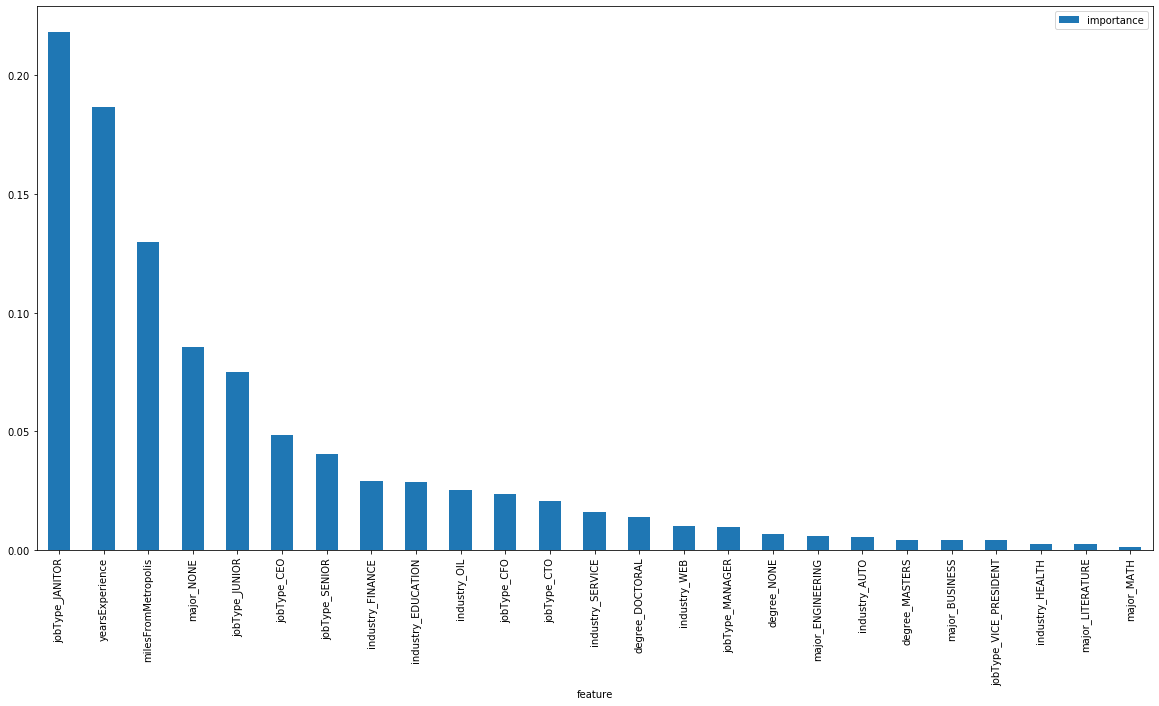
Github wont allow me to upload the data as it is very big.
The data can be found at: https://www.dropbox.com/sh/i9rdy7obsxcri1p/AAARI7cfTQHKHySKMyAY9a66a?dl=0
Drop me a request if you're not able to download the data