
Python package with command line utility to download files on any topic in bulk.
-
ctdl fetches file links related to a search query from Google Search.
-
Files can be downloaded parallely using multithreading.
-
ctdl is Python 2 as well as Python 3 compatible.
-
To install content-downloader, simply,
$ pip install ctdl $ pip install -U .
-
If you get error
ModuleNotFoundError: No module named ___then run all commands withpython ctdl/ctdl.py ___instead ofctdl ___ -
There seem to be some issues with parallel progress bars in tqdm which have been resolved in this pull. Until this pull is merged, please use my patch by running this command:
$ pip install -U git+https://github.com/nikhilkumarsingh/tqdm
$ ctdl [-h] [-f FILE_TYPE] [-l LIMIT] [-d DIRECTORY] [-p] [-a] [-t]
[-minfs MIN_FILE_SIZE] [-maxfs MAX_FILE_SIZE] [-nr]
[query]
Optional arguments are:
-
-f FILE_TYPE : set the file type. (can take values like ppt, pdf, xml, etc.)
Default value: pdf -
-l LIMIT : specify the number of files to download.
Default value: 10 -
-d DIRECTORY : specify the directory where files will be stored.
Default: A directory with same name as the search query in the current directory. -
-p : for parallel downloading.
-
-a : list of all available filetypes.
-
-t : list of all common virus carrier filetypes.
-
-minfs MIN_FILE_SIZE : specify minimum file size to download in Kilobytes (KB).
Default: 0 -
-maxfs MAX_FILE_SIZE : specify maximum file size to download in Kilobytes (KB).
Default: -1 (represents no maximum file size) -
-nr : prevent download redirects.
Default: False
-
To get list of available filetypes:
$ ctdl -a -
To get list of potential high threat filetypes:
$ ctdl -t -
To download pdf files on topic 'python':
$ ctdl pythonThis is the default behaviour which will download 10 pdf files in a folder named 'python' in current directory.
-
To download 3 ppt files on 'health':
$ ctdl -f ppt -l 3 health -
To explicitly specify download folder:
$ ctdl -d /home/nikhil/Desktop/ml-pdfs machine-learning -
To download files parallely:
$ ctdl -f pdf -p python -
To search for and download in parallel 10 files in PDF format containing the text "python" and "algorithm", without allowing any url redirects, and where the file size is between 10,000 KB (10 MB) and 100,000KB (100 MB), where KB means Kilobytes, which has an equivalent value expressed in Megabytes:
$ ctdl -f pdf -l 10 -minfs 10000 -maxfs 100000 -nr -p "python algorithm"
-
Install appJar. See appJar Widgets for info
pip install appjar==v0.61 pip install pyyaml -
Start GUI
python examples/gui.py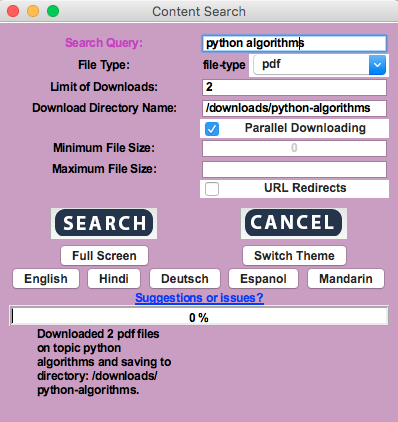
-
Automatically opens in a Finder window the directory containing the downloaded files when download completes
-
Internationalisation supported (currently includes English, Hindi, Deutsch, Espanol, Mandarin
-
Colour themes supported
-
Install Flask dependency:
pip install flask -
Start a Flask server in a Terminal Window No. 1:
python examples/server.py
-
Open another Terminal Window No. 2 and run cURL passing Query Parameters:
-
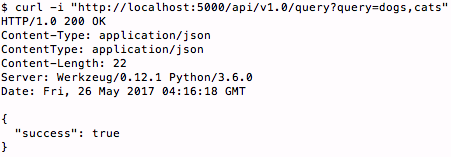
Example 1:
- Note: Defaults are applied for any missing parameters, as shown in logs of screenshot below.
The
queryvalues are mandatory.
curl -i "http://localhost:5000/api/v1.0/query?query=dogs,cats" - Note: Defaults are applied for any missing parameters, as shown in logs of screenshot below.
The
-
Example 2:
- Note: Explicitely override Defaults that would be otherwise applied
curl -i "http://localhost:5000/api/v1.0/query?query=dogs,cats&file_type=pdf&limit=5&directory=None¶llel=True&available=False&threats=False&min_file_size=0&max_file_size=-1&no_redirects=True"
-
-
Go back to Terminal Window No. 1 to see the Flask server process your downloads and and saves them in new folder 'dogs-cats' (which is named based on the query parameters)
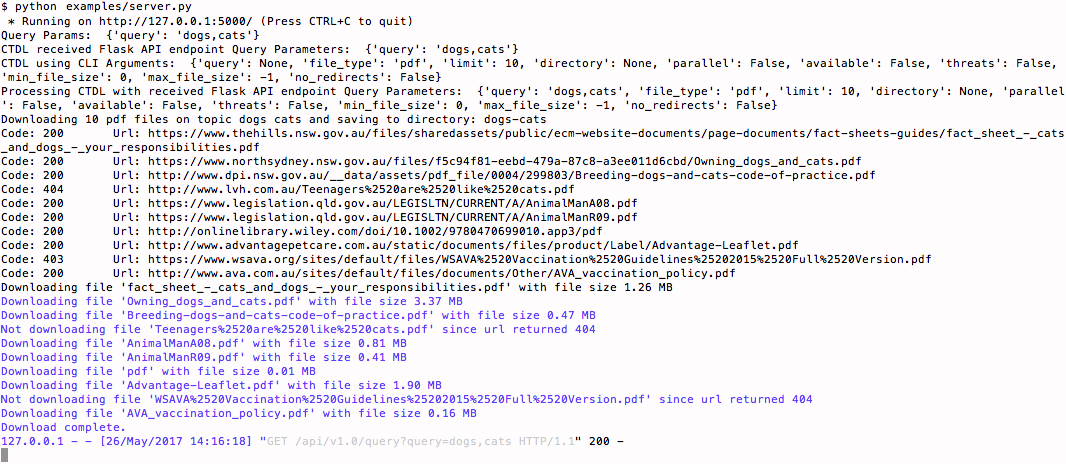
from ctdl import ctdl
filetype = 'ppt'
limit = 5
directory = '/home/nikhil/Desktop/ml-pdfs'
query = 'machine learning using python'
ctdl.download_content(query, filetype, directory, limit)- Prompt user before downloading potentially threatful files
- Example Flask server API implementation with query parameters
- Implement unit testing
- Create ctdl GUI (using appJar)
- Use DuckDuckgo API as an option
- macOS - Automatically open directory where files were downloaded when download completes
- Windows - Automatically open directory where files were downloaded when download completes
- Linux - Automatically open directory where files were downloaded when download completes
- Internationalisation - English, Hindi, Deutsch, Espanol, Mandarin
- Colour themes
- Accessibility with full screen mode
- Downloaded files saved in subdirectories of a 'downloads' directory that is generated at project root level
- Automatically populates directory input field with specific download directory to be generated based on query
-
Clone the repository
$ git clone http://github.com/nikhilkumarsingh/content-downloader -
Install dependencies
$ pip install -r requirements.txt
Note: There seem to be some issues with current version of tqdm. If you do not get expected progress bar behaviour, try this patch:
$ pip uninstall tqdm
$ pip install git+https://github.com/nikhilkumarsingh/tqdm
-
If you have any other issues running
ctdland loading modules then run the following (sincectdlcommand calls the PyPI ctdl package):$ pip install -U .-
If the problem still persists then in ctdl/ctdl.py, try removing the
.prefix from.downloaderand.utilsfor the following imports, so it changes from:from .downloader import download_series, download_parallel from .utils import FILE_EXTENSIONS, THREAT_EXTENSIONS
to:
from downloader import download_series, download_parallel from utils import FILE_EXTENSIONS, THREAT_EXTENSIONS
-
Also try running the python file directly with
python ctdl/ctdl.py ___(instead of withctdl ___)
-