Website Structure (Tutorial)
Goal: We analyse the structure of https://climate.nasa.gov/
Date: 2018-05-14
We browse to the URL of our Hyphe instance, we set the name of the new corpus, and click on CREATE PROJECT.

This new project is empty and there is not much to see. We will now create a web entity and crawl it.
We click on IMPORT in the left menu. This leads us to a page where we can create a web entity.
A web entity is a group of pages that we will consider as a whole. It is basically a website, but it can be whatever we want, even a single page. In this example we want to analyse the structure of https://climate.nasa.gov/, which is not the whole NASA website but only the “climate” part. We will define just this part of the NASA domain as a web entity.

In order to define this web entity we just copy-paste the URL representing it in the blue area. This interface supports lists and CSV spreadsheets, but it works as well with simple text.

We click on DEFINE WEB ENTITY which leads us to a screen where we have to set the boundaries of the web entity.

This screen usually displays a list, but here we just have one item. This item is a slider that we can move back and forth to set where are the boundaries of the web entity.
The slider is made of blocks corresponding to the elements of our URL. They are reordered from the most generic to the most specific, that is why we have the protocol first (https) then the “top level domain” (.gov), then de domain (nasa) and finally the subdomain (climate.). If the slider on the left, the entity will be more generic. If it is on the right, it will be more specific.
This step is necessary because the way a URL represents a web entity is usually not obvious. Hyphe cannot guess if we intended to analyse the full NASA website or just the climate section. So we have to set it right.
Since we want the climate section, the slider must bet set fully on the right, so that the preview title mentions “climate.Nasa.gov”, and the blue box encapsulates everything including “climate.”.

We click on CREATE WEB ENTITY and it is immediately created, though it is not crawled yet.

We will crawl this web entity. It means that Hyphe will download web pages inside this entity (and only inside it), and parse them to retrieve the hyperlinks they contain. To do so, we click on CRAWL WEB ENTITY.
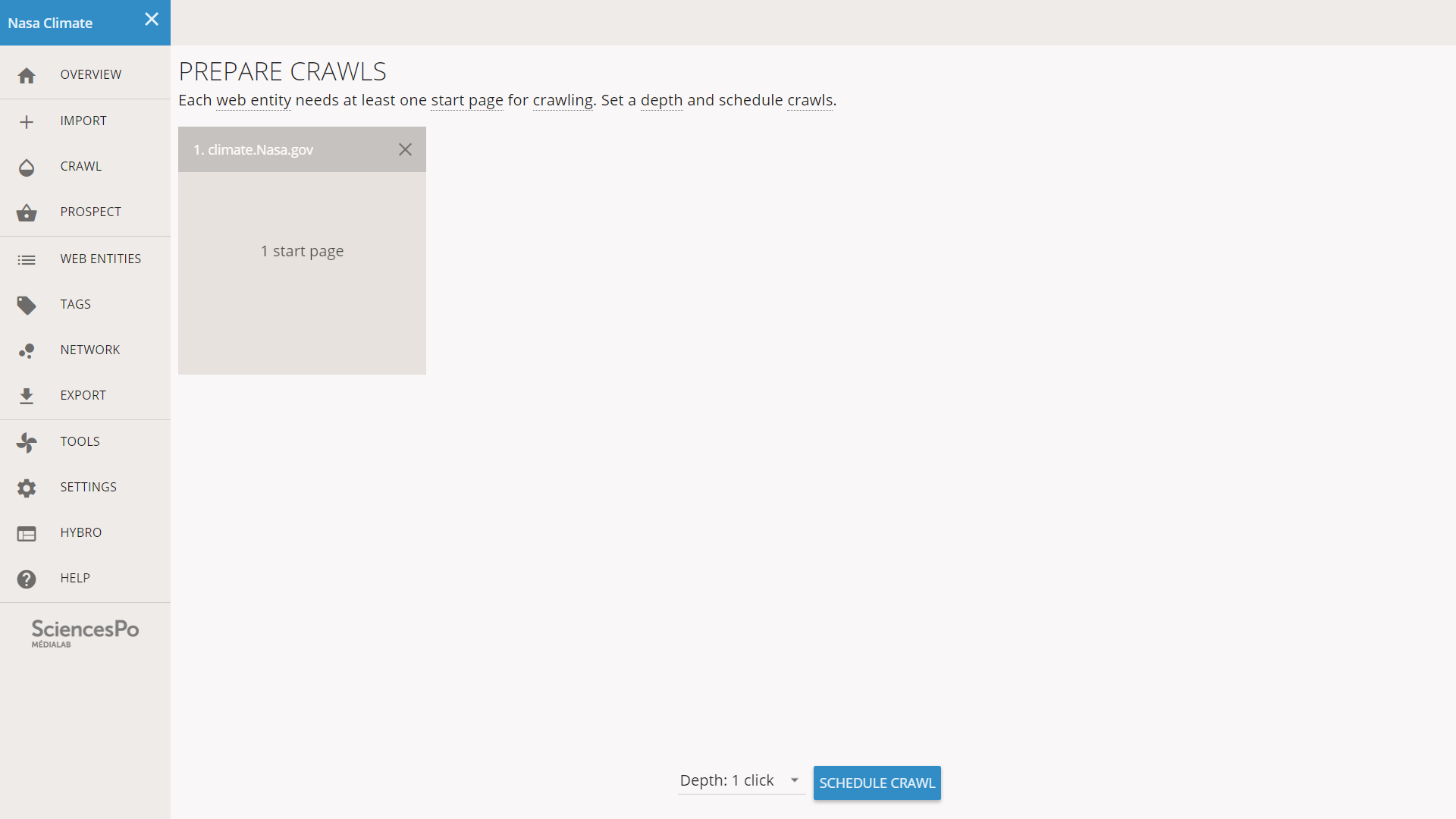
This screen is dedicated to preparing crawls. The square titled after our web entity helps to check that the crawl has a valid start page. It could be red if our start page was invalid. Here everything looks fine, the crawl can start.
Crawling requires a start page and here Hyphe will just use the URL we copy-pasted. It will follow the hyperlinks, find new pages, and crawl them iteratively. The crawl will stop at pages that are too far away from the starting page in number of clicks. We call this limit the “crawl depth” and it is the main setting of a crawl in Hyphe.
The dropdown menu at the bottom of the screen allows to set the crawl depth for the current batch. The default value depends on our configuration, here it is 1 click. We set it to 2 clicks. The number of pages to crawl augments exponentially with crawl depth, so it is important to use low value at first. If we do not have enough content for the analyse, then we will recrawl with a higher depth.
We click on SCHEDULE CRAWL, and the time that our single crawl job is sent to Hyphe, we are redirected to the CRAWL page where we can monitor the process.

We can always come back to this page by clicking on CRAWL in the left menu. It contains the list of all crawl jobs in the corpus, finished or not.
Crawl jobs have a life cycle:
- Pending: there is a waiting queue when there are too many crawl jobs.
- Crawling: Hyphe is downloading the pages.
- Indexing: Even after pages are downloaded, Hyphe needs time to process the data.
- Achieved / Canceled: the crawl job is finished or has been stopped.
We wait until the crawl job is finished. In our test it lasted 18 minutes for 317 pages crawled. The NASA website was pretty slow! It is usually worth crawling many web entities at the same time, since most of the time is spent waiting for the downloads.

We click on WEB ENTITIES in the left menu. It leads us to a list of the web entities present in our corpus.

We click on the small blue arrow on the right of our web entity to reach the screen dedicated to it.
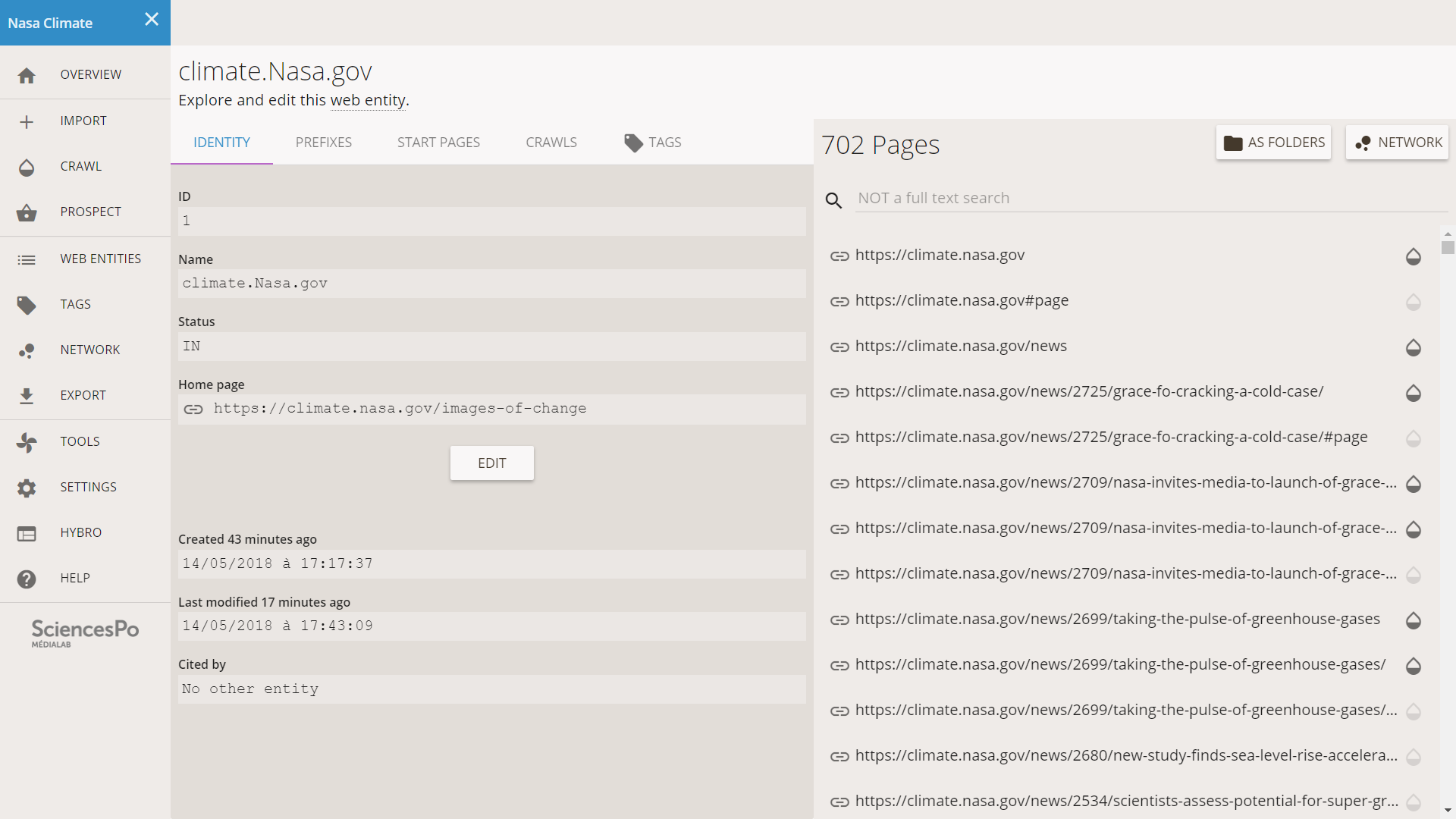
This page contains all the information that Hyphe knows about our web entity. The most interesting part is the list of pages on the right.
Note that Hyphe knows 702 pages about climate.Nasa.gov even though it only crawled 317. The additional ones are known because they are hyperlinked from known pages, but Hyphe did not crawl them because they were to deep. In our situation, it means that their depth is 3 clicks (since we stopped at 2).
There are two ways to look at the structure of the web entity: the network (it shows the links structure) and the folders (if shows the editorial structure). We access these by clicking on the buttons on the top right of the list of pages.
We click on NETWORK and reach a page displaying the network of pages. It only contains the pages inside the entity.
The dots represent the pages and the lines the hyperlinks. These links are oriented but it is not displayed in the image (the arrows would make it less readable). The size of the dots (pages) is proportional to how many neighbors they have. The red dot is the start page.
An algorithm is iteratively trying to set the position of nodes until a satisfying equilibrium is found. Once the network stops moving, we stop the algorithm by clicking on the animated button on the top left.

This screen can be used to have an idea of the structure of the layout. We can zoom in with the control buttons or the mouse wheel to read what are the pages. A qualitative analysis may not require a more sophisticated tool. It is also possible to download the network to analyze it in another software like Gephi (the download button is in the controls on the top-left of the network).

We can already have an idea of the network structure: a set of pages is in central position and seems strongly linked to the rest of the pages. It also see three “petals” around the center, that we interpret as three different areas that are not much linked to each other. More importantly, the number of uncrawled pages (small blue dots in peripheral position) is not very high. This indicates that it is probably safe to crawl the web entity deeper, and reveal a bigger part of its structure.
We decide that it is worth crawling deeper before pushing the analysis further. Anyway we want to take a look first at the folder structure of the entity.
We first go back to the screen about the web entity, and we now click on the AS FOLDERS button. This screen displays the content of the web entity as a tree of files and folders. What is represented here and where does it come from? A good way to figure it out is to look at an actual example of a URL:
https://climate.nasa.gov/news/2444/10-interesting-things-about-energy/
Most URLs make use of “/” (the slash character) as a separator between different parts. Note the exception of the first couple of slashes in the famous “http://” or here, “https://” (the secure version). The right part of URLs usually looks like a path in a file system. This is not actually mandatory and some website do not use this system, but it is widely used as a meaningful way to organize information. Hyphe leverages this situation to simplify browsing the content of a web entity. The current screen shows the URLs of the pages as if they were paths in a file system, which is usually (but not always) appropriate.

The root level of the tree contains the prefixes defining the web entity. We will not dig too much into this concept now but it is worth mentioning that these prefixes are used as a definition of a web entity. We have previously chosen the prefix defining our web entity as https://climate.nasa.gov/. In this interface we can see that Hyphe actually preemptively builds 3 additional variations of any prefix, which are in most cases defining the same web entity:
- Secure and without WWW: https://climate.nasa.gov/ (our original prefix)
- Non-secure and without WWW: http://climate.nasa.gov/
- Secure and with WWW: https://www.climate.nasa.gov/
- Non-secure and without WWW: http://www.climate.nasa.gov/
Not all of these prefixes are necessarily used by the web entity, but we cannot predict which are relevant. This is why Hyphe generates the 4 variations by default. As we can see in our screen, the secure-non-WWW version contains 603 pages while the non-secure-non-WWW version contains 97, and the others none.
These prefixes may or may not be pages (it is possible that they define a web entity while the page itself is not valid). In this screen we see that 2 of these prefixes are also pages.
The screen also mentions a “parent web entity”: Nasa.gov. We will skip the detailed explanation for now, but it is worth mentioning that our entity (climate.Nasa.gov) is NOT contained inside the parent entity. Entities cannot contain each other. Pages of climate.Nasa.gov are not belonging to Nasa.gov.
We click on the most used prefix, the first one (they are sorted by decreasing number of pages). We now see the different “folders” it contains: news, blog, climate_resources, internal_resources, system… There are 34 of them, though not all of them contain many different pages.

This level of folders provides a rich information about the content of the website. The folder containing the most pages (273) is “news”. This website seems to dedicate a large part of its content production to news. The second most represented category is “blog” (61 pages) followed by “climate_resources” and “internal_resources”. What are these two categories?
We click on “climate_resources” and we see that it contains folders that are just numbers. We click on one at random (“24”) and we realize that it contains a subfolder named “graphic-the-relentless-rise-of-carbon-dioxide”. Each number seems to be an identifier for a resources that is also named more explicitly in the subsequent folder level.
We click on the link icon to browse the content (see image below). The page presents a downloadable document about carbon dioxide and provides useful context such as a detailed description and the source of the document. As expected from the NASA, their sources are well organized and documented.

As we mentioned earlier, we want to crawl deeper before pushing the analysis further.
We click on WEB ENTITIES in the left menu and we check on the web entity in the list (there is only one item). The right panels offers different options for the selection, including the CRAWL button.

We click on the CRAWL button and follow the same steps as before, except that we now set the crawl depth to 4 clicks. The crawl page now displays a second crawl job for the same entity.

40 minutes later, the crawl is achieved and 710 pages have been crawled in total.
The network of pages looks like this in Hyphe:

We downloaded the file to analyse it further in Gephi. We looked at which nodes are the most cited (by other pages in this web entity) and explore the network more in detail. Generic Gephi tutorials available online explain how to do so.
A coherent entity. The network of pages is well connected and has a core-periphery structure. We do not observe remote clusters or major divides. The network is not made of loosely connected parts, but of a single whole of well hyperlinked pages. The 738 crawled pages have 14,610 hyperlinks between them, about 20 links per page.
A core of 28 pages. As visible in the image above, a set of 28 pages is much more connected than the rest (the bigger dots in the middle). It is identified as the “menu” pages in the structure of the website. First of all there is a clear gap in the number of citations (indegree) since these 28 are cited 378 times or more while the rest is 171 times or less. A similar gap is also apparent in the outdegree, where 359 pages cite 0 to 5 pages while the 379 others cite at least 29 other pages (we only counted crawled pages here). After a quick check we believe that most pages with few outbound links are resources like images or animations that are generally embedded in a page with a menu and additional content, but can also be browsed as a separate page.
Specific subspaces: the blog, “explore”, and the recent news. The set of nodes around the center seems to have three “bumps” pointing in three directions. A community detection algorithm in Gephi (modularity clustering) identifies two of them as specific subspaces. By looking at which pages are gathered in each of these subclusters, we identify them as the blog and the “explore” section that gathers key resources like videos or scrollytellings. The rest of the pages (core and periphery) is identified as a single subcluster but a small subset of pages clearly emerges as massively cited by other pages (over 100 times). Browsing them reveals that they were all recent: we hypothesize that these are pushed as recommendations because for that reason. The image below summarizes how we broke down the structure.

The three different parts are distinct but partially intertwined. The menu is proposing clear cut categories: Facts, Articles, Solutions, Explore, Resources, and Nasa Science, and these items also have subcategories. However this editorial structure does not match the hyperlink structure of the websites. In order to render this structure visible, we removed the 28 menu pages from the Gephi network. These pages were creating links between the other pages just because they were cited from everywhere. Once removed, a much clustered structure appears. As pictured in the image below, we identify the three parts previously evoked: the blog, the news, and the “explore” (key documents). We can interpret these clusters as the strategy adopted by the website to incentivize navigation: the most important navigation path is the menu and it can lead from a subspace to another (transversal navigation) while the second most incentivized path is inside each subspace (local navigation). Remarkably, a third kind of navigation plays an important role: content-related links, in the original sense of hypertext navigation, sometimes connecting pages of different subspaces. The website is not just a platform offering structured contents, it is also highly editorialized and its authors have manually created hyperlinks between various resources.

Pages of climate.Nasa.gov without the 28 menu pages. Node size by degree. Node color by modularity clustering.
Three key resources bridging subspaces. Using the betweenness centrality as a measure of bridging, we can identify which web pages play a key role in content navigation. As we can see in the image below, a group of three pages create a strong connexion between the “explore” resources and the news. Each of these is an interface containing different resources organized as an exploration tool focused on a specific idea. The Global Ice Viewer displays maps and charts about glacier loss. Images of Change allows to compare aerial views in a “before/after” fashion. The Climate Time Machine focuses on timelines and the evolution of phenomena like sea level rise. We assume that these three interactive devices are key to the website, where they the most central role if we look at the content links, disregarding the menu pages.
 Pages of climate.Nasa.gov without the 28 menu pages.
Node size by betweenness centrality. Node color by modularity clustering.
Pages of climate.Nasa.gov without the 28 menu pages.
Node size by betweenness centrality. Node color by modularity clustering.
 Screenshot of the Global Ice Viewer
Screenshot of the Global Ice Viewer
 Screenshot of Images of Change
Screenshot of Images of Change
 Screenshot of the Climate Time Machine
Screenshot of the Climate Time Machine
To download a file, use right-click => Save as... (or similar)