This repository supports training and evaluating of Universal Embeddings for fine-grained and instance-level recognition across diverse domains. The experiments in the respective ICCV publication can be replicated using the code provided in this repository. The implementation relies on the Scenic computer vision library, which is based on JAX and Flax.
Project webpage (includes UnED splits): https://cmp.felk.cvut.cz/univ_emb/
- Make sure to use Python 3.9
- Create Virtual Environment:
python3.9 -m venv uned_venv - Activate the Virtual Environment:
source uned_venv/bin/activate - Clone scenic:
git clone https://github.com/google-research/scenic.git - Install scenic dependencies:
cd scenic && pip install .Keep in mind that you might need to modify the installation of Jax used depending on the type of your accelerator (CPU, GPU, TPU). - clone the UnED repo:
git clone https://github.com/nikosips/Universal-Image-Embeddings.git cd Universal-Image-Embeddingspip install wandb
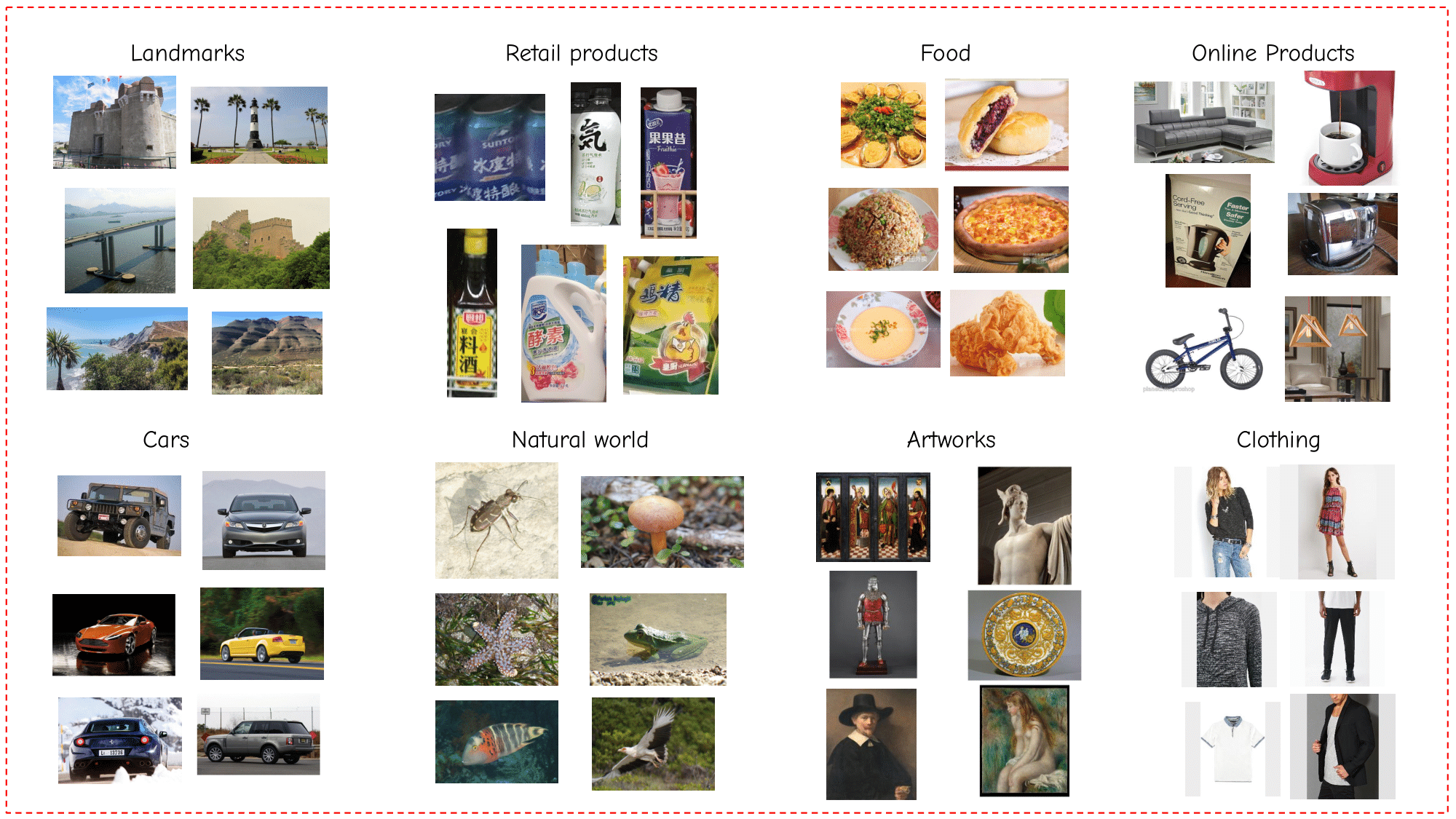
The UnED dataset consists of 8 existing datasets, with new splits proposed. We provide guidelines for how to prepare all the data that are used for training and evaluation.
-
Create
datadirectory inside the "Universal-Image-Embeddings" directory. -
Download the splits of UnED (info files) (https://cmp.felk.cvut.cz/univ_emb/info_files.zip) and extract it inside the data directory.
-
Download (https://cmp.felk.cvut.cz/univ_emb/#dataset) and extract images for each one of the datasets comprising UnED, into
data/imagesdirectory. You should follow the URL provided for each one of the datasets, in order to get the images of it. If you encounter any problems downloading any of the datasets from their original sources that we have linked, please contact us in order to help you.data/imagesdirectory should end up with the following structure (should contain the directories as shown below in order to work with the info files provided later):├── images │ ├── cars │ │ └── car_ims │ ├── food2k │ │ └── Food2k_complete │ ├── gldv2 │ │ ├── images │ │ │ ├── index │ │ │ ├── test │ │ │ └── train │ ├── inat │ │ ├── iNaturalist │ │ │ └── train_val2018 │ ├── deepfashion │ │ ├── inshop │ │ │ └── img │ ├── met │ │ ├── MET │ │ ├── test_met │ │ ├── test_noart │ │ └── test_other │ ├── rp2k │ │ ├── all │ │ │ ├── test │ │ │ └── train │ └── sop │ ├── chair_final │ └── ... -
Download the checkpoints that are used as a starting point for the finetuning (https://cmp.felk.cvut.cz/univ_emb/#checkpoints) and place them inside the
modelsdirectory, by running the following command:bash download_models.sh -
Create the tfds records that are used to load the data for training and evaluation by running the following command:
bash prepare_data.sh
In the end, data folder should look like this:
├── Universal-Image-Embeddings
│ ├── data
│ │ ├── images
│ │ ├── info_files
│ │ ├── models
│ │ └── tfds
Now that the data are ready, you are ready to train and evaluate embeddings on the UnED dataset.
-
Embedding training and validation (and optional final testing)
Configure the "config_train_vit.py" to the type of training you want to perform. Checkpoints, embeddings and event files are saved in
YOUR_WORKDIR. Wandb flags are optional if you want to log training and validation metrics to wandb, otherwise, you can view them in tensorboard, through the event file that is saved in the workdir.python -m universal_embedding.main \ --config=universal_embedding/configs/config_train_vit.py \ --workdir=[YOUR_WORKDIR] \ --config.eval_dataset_dir=data/tfds \ --config.train_dataset_dir=data/tfds \ --config.info_files_dir=data/info_files \ --wandb_project [WANDB PROJECT NAME] \ --wandb_group [WANDB GROUP NAME] \ --wandb_entity [WANDB ENTITY NAME] \ --wandb_name [WANDB EXPERIMENT NAME] \ --use_wandb -
Evaluation of embeddings trained with this repository
Configure the "config_knn_vit.py" to the type of evaluation you want to perform. Configure config.train_dir in the config file to the directory that the checkpoint of the training is saved (the config.json of the training must also exist there). Descriptors and event files are saved in
YOUR_WORKDIR.python -m universal_embedding.knn_main \ --config=universal_embedding/configs/config_knn_vit.py \ --workdir=[YOUR_WORKDIR] \ --config.eval_dataset_dir=data/tfds \ --config.train_dataset_dir=data/tfds \ --config.info_files_dir=data/info_files \ --config.train_dir=[MODEL TRAIN DIR] -
Evaluation of your own embeddings on the UnED dataset
Configure the "config_descr_eval.py" to the type of evaluation you want to perform. Event files are saved in
YOUR_WORKDIR.python -m universal_embedding.descr_eval \ --config=universal_embedding/configs/config_descr_eval.py \ --workdir=[YOUR_WORKDIR] \ --config.eval_dataset_dir=data/tfds \ --config.train_dataset_dir=data/tfds \ --config.info_files_dir=data/info_files \ --config.descr_path=[DESCRIPTORS PATH] -
Extraction of embeddings on your own images using models trained on UnED
Configure the "config_extract_dir_descriptors.py" to the type of descriptor extraction you want to perform. Configure config.base_dir to the directory that contains the images that you want to extract descriptors for. Configure config.train_dir in the config file to the directory that the checkpoint of the training is saved (the config.json of the training must also exist there). Descriptors will be saved in
WORKDIR.python -m universal_embedding.extract_dir_descriptors \ --config=universal_embedding/configs/config_extract_dir_descriptors.py \ --workdir=[YOUR_WORKDIR] \ --config.train_dir=[MODEL TRAIN DIR] \ --config.base_dir=[DIR OF YOUR IMAGES]
Each subdomain of the UnED dataset (e.g. CARS or Met) defines its own train, validation and test set.
You can perform knn evaluation on these splits of each dataset, by using the proposed query and index subsplits of each split.
Those subsplits are defined in the datasets.py script,
For example, for the CARS domain, the subsplits are:
'knn': {
'train_knn': {
'query': 'train',
'index': 'train',
},
'val_knn': {
'query': 'val',
'index': 'val',
},
'test_knn': {
'query': 'test',
'index': 'test',
},
},
which means that in order to perform knn evaluation on the validation split, the validation split acts as both the query and the index set.
As another example, for Met domain the subsplits for knn evaluation are:
'knn': {
'train_knn': {
'query': 'train',
'index': 'train',
},
'val_knn': {
'query': 'val',
'index': 'small_index',
},
'test_knn': {
'query': 'test',
'index': 'index',
},
}
which means that in order to do knn evaluation on the test split, the query set is the test set of the Met dataset, while the index set for the test split comes from the index set of the Met dataset. Those image sets are created when the tfds records are formed. To see to which exactly they correspond, look at prepare_data.sh script.
If you want to extract embeddings with your own model to evaluate them using the descr_eval.py script, the embeddings should be provided in json format, in a dictionary with the following structure:
For CARS:
'cars': {
'train': [list of descriptors for this split],
'val': [list of descriptors for this split],
'test': [list of descriptors for this split],
},
or for Met:
'met': {
'train': [list of descriptors for this split],
'val': [list of descriptors for this split],
'small_index': [list of descriptors for this split],
'index': [list of descriptors for this split],
'test': [list of descriptors for this split],
},
or subsets of the above that coincide with the splits you want to perform knn evaluation on.
In the case of performing knn evaluation across many domains, it is always performed on the same split across datasets (e.g. train, validation or test). Two types of knn evaluation are supported in that case. "Separate" evaluation means that each dataset is evaluated on its own (the queries are compared against their index of their own domain), while "merged" evaluation means that the index sets of the corresponding splits across all domains are merged (the queries of each domain are compared against the merged index set). The latter, on the test split across all 8 domains corresponds to the standard evaluation protocol of the UnED benchmark.
The repository will be updated for some time, in order to provide an easier interface for training and evaluation. New features will be added soon to make the use of the UnED dataset easier, as well as to improve ease of evaluating embeddings on it.
- The words "embeddings" and "descriptors" are used interchangeably in the context of this repository.
- With the current setup you can not do knn on the train splits, due to the shuffling performed on the train tfds
- Provide ICCV checkpoints for universal models (need to store the config files of training as well, because they will be needed to re-init the model)
- Add descriptor extraction for an ImageDir dataset
- Support continuing training from a checkpoint
- Update the knn script to newer version
- remove the dependency on the uned dataset tfdses for descr_eval.py
If you use our work in yours, please cite us using the following:
@InProceedings{Ypsilantis_2023_ICCV,
author = {Ypsilantis, Nikolaos-Antonios and Chen, Kaifeng and Cao, Bingyi and Lipovsk\'y, M\'ario and Dogan-Sch\"onberger, Pelin and Makosa, Grzegorz and Bluntschli, Boris and Seyedhosseini, Mojtaba and Chum, Ond\v{r}ej and Araujo, Andr\'e},
title = {Towards Universal Image Embeddings: A Large-Scale Dataset and Challenge for Generic Image Representations},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {11290-11301}
}
We appreciate the help of Elias Ramzi on making the repository easier to use and spotting some bugs that existed in the initial version. Also, the repository is inspired by the codebase of Poly-ViT .