- std:: array std::array는 반족자(iterator)와 범위 기반 for(range_based for) 문법을 이용하여 원소에 차례대로 접근할 수 있다.
- front() : 배열의 첫 번째 원소에 대한 참조를 반환.
- back() : 배열의 마지막 원소에 대한 참조.
- data() : 배열 객체 내부에서 실제 데이터 메모리 버퍼를 가리키는 포인터를 반환.
array에 대해 관계 연산자를 사용할 경우, 두 배열의 크기가 같아야 한다. 이는 array로 생성한 배열 객체의 경우, 배열의 크기가 데이터 타입 일부로 동작하기 때문이다. 즉, 크기가 다른 배열은 서로 다른 타입으로 인식되어 비교할 수 없다.
array는 c 스타일 배열의 향상된 버전이지만 실제로 유용한 기능을 제공하지 않는다. array의 크기는 컴파일 시간에 결정되는 상수이어야 하며, 프로그램 실행 중에 그 크기는 변경할 수 없다. 크기가 고정되어 있기에 원소를 추가하거나 삭제가 불가하다. array의 메모리 할당 방법을 변경할 수 없으며 항상 스택 메모리를 사용해야 한다.
std::array<int,5> arr = {1,2,3,4,5};
//auto 이용하는 방법 1
for(auto element : arr) std::cout << element << ' ';
for(auto it = arr.begin(); it != arr.end(); it++)
{
auto element = (*it);
std :: cout << element << ' ';
}
cout << arr.front() << endl; //1
cout << arr.back() << endl; //5
cout << *(arr.data() +1) << endl // 2- std::vector
벡터는 원소 크기를 지정하지 않고 선언할 수 있으며 벡터의 크기를 명시적으로 지정하지 않거나 또는 초깃값을 지정하여 크기를 유추할 수 있게 코드를 작성하지 않을 경우 컴파일러 구현 방법에 따른 용량을 갖는 벡터가 생성된다. 벡터의 크기는 벡터에 실제로 저장된 원소 개수를 나타내는 용어이며, 용량과는 다른 의미를 갖는다.
- push_back() : 벡터의 맨 마지막에 새로운 원소를 추가한다. 해당 함수는 매우 빠른 연산이며 평균 시간 복잡도는 O(1)에 가깝다.
- insert() : 삽입할 위치를 나타내는 반복자를 첫 번째 인자로 받음으로써 원하는 위치에 원소를 추가할 수 있다. 원소들을 이동하는 연산이 있기 때문에 insert() 함수는 O(n)의 시간이 걸린다.
- pop_back() : 벡터에서 맨 마지막 원소를 제거하며, 그 결과 벡터 크기는 1만큼 줄어든다. 시간복잡도는 O(1)이다.
- erase() : 두 가지 형태로 오버로딩되어 있다. 한가지 형태는 반복자 하나를 인자로 받아 해당 위치 원소를 제거하고, 다른 형태는 범위의 시작과 끝을 나타내는 반복자를 받아 시작부터 끝 바로 앞 원소까지 제거한다. 시간 복잡도는 O(n)이다.
- clear() : 모든 원소를 제거하며 빈 벡터로 만든다.
- reserve : 재할당.
- shrink_to_fit() : 여분의 메모리 공간을 해체하는 용도로 사용한다. 벡터 크기가 더 이상 변경되지 않을 때 사용하면 유용하다.
*** 벡터는 push_front() 함수를 지원하지 않는다. 맨 앞에 새로운 원소를 추가하려면 원소 삽입 위치를 인자로 받는 insert() 함수를 사용해야 한다.
vector<int> vec; //크기가 0인 벡터 선언.
vector<int> vec = {1,2,3,4,5}; //크기가 5인 벡터 선언.
vector<int> vec(10); //크기가 10인 벡터 선언.
vector<int> vec(10,5); //크기가 10이고, 모든 원소가 5로 초기화된 벡터 선언.
vector<int> vec; //{}
vec.push_back(1); //{1}
vec.push_back(2); //{1,2}
vec.insert(vec.begin(),0) //{0,1,2}
vec.insert(find(vec.beigin,vec.end(),1),4); // 1앞에 4 추가 {0, 4, 1, 2}
vec.pop_back(); //{0,4,1}
vec.erase(vec.begin()); //{4,1}
vec.erase(vec.begin(),vec.end()) //{}- std::forword_list
vector에서 원소를 삽입할 때와는 조금 다르게 동작한다. push_front()함수를 지원하지만 push_back() 함수는 제공하지 않는다. 특정 위치에 원소를 삽입하는 insert()가 아니라 insert_after()함수를 사용해야 한다.
deque<int> deq ={1,2,3,4,5};
deq.push_front(0);
deq.push_back(6);
deq.insert(deq.begin()+2,10);
deq.pop_back();
deq.pop_front();
deq.erase(deq.begin()+1);
deq.erase(deq.begin() +3, deq.end());-
std::list
-
std::deque
- push_front(), pop_front(), push_back(), pop_back() 동작이 O(1) 시간 복잡도로 동작한다.
stack은 스택이 기본저그올 제공해야 할 기능을 empty(),size(),top(),push(),pop(),emplace()등의 함수로 제공한다.
원소를 제거하고(pop()), 추가하고(push()) deque을 기본 컨테이너로 사용하며, 모든 함수는 시간 복잡도 O(1)로 동작한다.
우선순위 큐는 힙이라고 부르는 매우 유용한 구조를 제공한다. 힙은 컨테이너에서 가장 작읍 원소에 빠르게 접근할 수 있는 자료 구조이며, 최소/최대 원소에 접근하는 동작은 O(1)의 시간 복잡도를 가진다. 원소 삽입은 O(log n) 시간 복잡도로 동작하며, 원소 제거는 최소/최대 원소에대해서만 가능하다.
한 시작점 노드(v)에서 연결된 모든 노드 (w1,w2,w3)들 중 w1부터 탐색하는데 한번 w1를 탐색하면 해당 노드(w1)에 연결된 노드들을 우선적으로 찾아 계속 연결된 노드를 탐색한다. w1의 탐색이 완료되면 다시 v기준으로 w2를 탐색하고 이를 반복한다.
#include <string>
#include <vector>
using namespace std;
int answer = 0;
void DFS(vector<int> numbers,int target,int sum,int count)
{
if(count == numbers.size())
{
if(sum == target) answer++;
return;
}
DFS(numbers,target,sum+numbers[count],count+1);
DFS(numbers,target,sum-numbers[count],count+1);
}
int solution(vector<int> numbers, int target)
{
DFS(numbers,target,0,0);
return answer;
}int gcd(int n,int m)
{
int c;
while( m != 0)
{
c = n % m;
n = m;
m = c;
}
return n;
}
int lcm(int n, int m)
{
return n * m / gcd(n,m);
}프로그래머스를 풀다가 문자열에서 정수들을 추출해야 하는 경우가 많이 발생한다. 문자열은 정말 지옥이다. 그러다가 string을 토큰으로 분리할 수 있는 stringstream에 대해 알게 되었다.
stringstream은 공백을 기준으로 string을 뽑아낼 수 있으며, 심지어 음수, 양수를 구분하여 뽑아낼수 있다.
stringstream은 오픈채팅방이라는 문제를 풀면서 알게된 클래스이며 헤드는 을 갖는다. 문자열에서 실수와 정수를 추출할 때 'intBuff' 와 'doubleBuff' 으로 추출할 수 있다.
[Level2] 2019 KAKAO BLIND RECRUITMENT - 오픈채팅방
#include <iostream>
#include <sstream>
using namespace std;
int main(void)
{
int intBuff;
double doubleBuff;
stringstream ss;
ss.str("123 56.7);
ss >> intBuff >> doubleBuff; // intBuff= 123 doubleBuff=56.7
ss.clear();
ss.str("12+32-98+23");
int buff;
while(ss >> buff) // buff = 12 -> 32 -> -98 -> 89 -> 71
return 0;greedy algorithm은 문제를 해결하는 과정에서 그 순간순간마다 최적이라고 생각되는 결정을 하는 방식으로 진행하여 최종 해답에 도달하는 문제 해결 방식이다.
상당수의 분할 정복 기법(큰 문제를 작은 여러개의 문제로 나누어 푸는 기법으로 재귀적 성격을 띔)은 동일한 문제를 추후 다시 푼다는 단점을 가지고 있다.
동적 계획법을 사용할 수 있는 가정 큰 문제를 작은 문제로 나눌 수 있어야 한다. 마치 피보나치 수열처럼. 큰 문제들은 작은 문제들로 이루어진다. 작은 문제들로 분할이 가능. 단, 큰 문제와 작은 문제의 관계에서 사이클이 발생해선 안된다.작은 문제에서 구한 정답은 그것을 포함하는 큰 문제에서도 동일하다. 즉, 점화식을 세울 수 있어야 한다. 4 를 구하는 과정에서 구해서 저장했던 3 을, 5 를 구하는 과정에서도 그대로 쓸 수 있는 문제여야 한다. 동일하게.
소수를 판별하기 위해 에라토스테네스의 체를 이용한다. 에라토스테네스의 체를 간단히 설명하자면, 2부터 n까지의 수 중에 소수를 판별하기 위한 알고리즘이다. 소수를 찾으면 해당 수의 배수를 모두 지워나가는 방식이다.

bool isPrime(int n)
{
if(n < 2) return false;
for(int i = 2; i <= sqrt(n) ; i++) if(n % i == 0) return false;
return true;
}수학적으로 순열이란 서로 다른 n개의 원소에서 r개를 뽑아 한 줄로 세우는 경우의 수를 말한다. 원소를 한 줄로 세우기 때문에 원소의 조합이 같더라도 순서가 다르면 다른 방법으로 본다.
ex) {1, 2, 3}의 원소들의 모든 순열을 구한다면 {1, 2, 3}, {1, 3, 2} {2, 1, 3} {2, 3, 1} {3, 1, 2} {3 2 1} 으로 총 6가지가 나온다.
c++ 의 헤더에는 n개의 원소의 순열을 구할 수 있는 next_permutation이라는 함수가 있다. 기본적 문법은 다음과 같다.
bool next_permutation(BidirectionalIterator first, BidirectionalIterator last};
bool next_permutation(BidirectionalIterator first, BidirectionalIterator last,compare comp};next_permutaion을 사용할 때는 몇 가지 주의할 점
- 오름차순으로 정렬된 값을 가진 컨테이너로만 사용가능하다.
- defalut로 operator <를 사용해 순열을 생성한다.
- 중복이 있는 원소들은 중복을 제외하고 순열을 만들어준다.
next_permutation 사용 예시
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
vector<int> v{ 1, 2, 3};
sort(v.begin(), v.end());
do {
for (auto it = v.begin(); it != v.end(); ++it)
cout << *it << ' ';
cout << endl;
} while (next_permutation(v.begin(), v.end()));
}unordered_map
unordered_map은 hash_table 기반의 hash container입니다.
hash_table을 통해 참조를 하기 때문에 각 node들을 정렬할 필요가 없습니다.
따라서 충분한 hash_table의 크기만 주어진다면 데이터 양이 많아지더라도 Search / Insert / Delete 성능을 꾸준하게 보장할 수 있습니다.
성능 비교
map 과 hash_map 은 알고리즘 특성 상 키의 데이터 타입이 숫자일 때와 문자열일 때 현격한 차이를 보입니다.
따라서 성능 비교도 숫자형 키를 사용할 때와 문자열 키를 사용할 때를 따로 비교해야 합니다.
아래와 같이 container에 데이터를 insert 한 뒤 find를 반복적으로 수행한 시간을 기록합니다.
X 축은 데이터 크기 N, Y 축은 탐색 1회에 걸린 시간(마이크로초) 입니다.
map은 O(logN) 의 시간복잡도를 보이며 급격히 소요시간이 증가한 구간은 캐시 미스로 인해 발생한 것으로 추측됩니다.
그에 반해 unordered_map 은 O(1) 의 시간 복잡도를 보여줍니다.
이처럼 숫자형 키를 사용할 경우 데이터의 양이 많아질수록 unordered_map이 월등한 성능을 보여주게됩니다. Key Type : const char*
문자열을 키로 사용할 경우는 조금 복잡합니다.
map은 insert 할 때 key를 기반으로 정렬하게 되는데 문자열 비교 함수의 성능은 문자열 전체를 hashing 하는 것에 비해 우수합니다.
그것은 문자열 전체를 비교하지 않고 앞에서부터 한글자씩 차례로 비교하여 크고 작음을 가려내기 때문에 문자열의 길이가 길어지더라도 민감하게 반응하지 않습니다.
key value들의 분포가 고르게 형성되어 있어 앞의 몇 글자만 비교해서 우열이 가려질 가능성이 있기 때문이죠.
예를 들어 문자열 key의 집합이 다음과 같다고 했을 때,
black, blue, cyan, gray, green, lime, magenta, maroon, navy, olive, purple, red, silver, teal, white, yellow
앞의 1~2글자만 비교하면 대부분의 문자열 비교가 끝나게 됩니다.
반면 문자열의 길이가 길어지면 key를 hashing 하는 unordered_map의 경우 성능에 영향을 상대적으로 많이 받게 됩니다.
따라서 문자열의 길이를 4, 8, 12, 16 으로 측정을 했을 때 아래와 같은 결과를 확인할 수 있습니다.
X 축은 데이터 크기 N, Y 축은 탐색 1회에 걸린 시간(마이크로초) 입니다. 기본적으로 숫자형 key와 비슷한 양상을 보이며, 문자열 길이가 커짐에 따라 교차점이 달라짐을 확인할 수 있습니다.
물론 key의 집합이 다음과 같이 접두사가 비슷한 경우라면 map도 문자열 길이의 영향을 더 크게 받게 됩니다.
abnormal, abnomality, abnomalities, abnormalization
그렇기 때문에 키 값을 timestamp를 이용해 만들어 사용하는 경우에 문자열의 앞부분이 같은 표본이 대량으로 생성되어
비교함수의 성능이 떨어지므로 지양해야 합니다. (실제 사례)
결론 데이터가 많은 경우에는 unordered_map 이 map 보다 성능면에서 유리합니다. 문자열을 키로 사용하는 경우 문자열이 길어질 수록 unordered_map 이 map에 비해 더 성능이 떨어질 수 있습니다. 유사도가 높은 문자열 집합을 키로 사용하는 경우에 map 의 성능이 떨어질 수 있습니다.
결론적으로 key를 이용하여 정렬을 해야 하는 경우를 제외하고 대량의 데이터를 저장할 때는 unordered_map 을 사용하는걸 추천합니다.
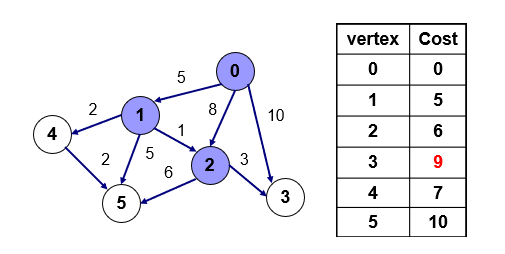
다익스트라 알고리즘은 한점을 기준으로 나머지 모든 점에 대해서 최단거리를 구하는 것.
다익스트라는 모든 가중치가 음수가 아닐때만 사용이 가능하다.
기본원리 :
- 방문하지 않은 점중 값이 가장 작은 점을 방문한다.
- 그 점을 통해서 갈 수 있는 점 중에서 아직 방문하지 않은 점의 값이 이전에 기록한 값보다 작으면 그 거리를 갱신한다.

cost는 해당 점을 가기 위한 값을 기록하는 배열이며, 0번을 시작점으로 해서 0번에서 갈 수 있는 모든점에 대해 최단거리를 구하는 것이다.
아직 각 점들에 대한 거리를 모르기때문에 무한대로 초기화한다.

0번 점을 방문하고 0번점에서 갈 수 있는 1,2,3번 점에대해 기존에 cost배열에 있는 값과 0에서 가는 값을 비교해서 작을 경우 갱신해준다.

방문하지 않은 점 1,2,3,4,5 중에서 값이 가장 작은 점 1 을 방문한다. 1을 통해서 갈 수 있는 점 2,4,5 에 가는 거리는 0번에서 1번으로 가는 거리 5에서 1에서 각 점으로 가는 거리 1,2,5를 더해준다.
2,4,5 모두 ㅂ을 통해서 가는 거리가 더 짧음으로 2,4,5 점의 값을 갱신해준다.



#include <iostream>
#include <vector>
#include <queue>
#define INF 1e9
using namespace std;
int solution(int N, vector<vector<int> > road, int K) {
int answer = 0;
vector<pair<int,int>> table[51];
vector<int> dist(51,INF); /*최단거리를 갱신해주는 배열 , dist 값을 무한대로 초기화*/
priority_queue<pair<int,int>> pq;
for(auto v : road)
{
table[v[0]].push_back({v[1],v[2]}); /*from, to, value*/
table[v[1]].push_back({v[0],v[2]}); /*from, to, value*/
}
pq.push({0,1});/*우선 순위 큐에 시작점과 cost 삽입*/
dist[1] = 0; /*시작점의 최단거리를 갱신*/
while(!pq.empty())
{
int cost = pq.top().first; /*cost는 다음 방문할 점의 dist*/
int cur = pq.top().second; /*cur을 방문할 점의 번호*/
pq.pop();
for(int i=0; i< table[cur].size(); i++)
{
int next = table[cur][i].first;
int next_cost = table[cur][i].second;
if(dist[next] > dist[cur] + next_cost)
{
dist[next] = dist[cur] + next_cost;
pq.push({-dist[next],next});
}
}
}
for(int i=1; i<=N; i++) /*문제 조건 대입*/
{
if(dist[i] <= K) answer++;
}
return answer;
}