Design
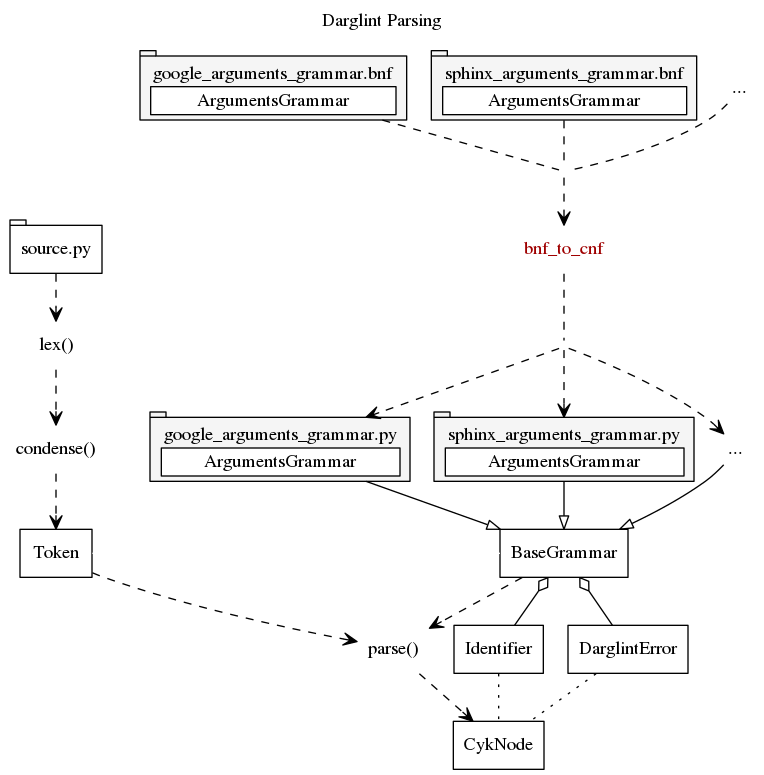
Below is a high level overview of darglint.

A source file is first parsed by darglint's parser (described below), and also
parsed by Python's ast module in the wrapper class, FunctionDefinition.
The resulting docstring AST and the FunctionDefinition are passed to the class,
IntegrityChecker, which checks the integrity of the docstring against the
actual function, and issues a resulting ErrorReport.
The IntegrityChecker can have multiple functions passed to it from multiple
files. To increase throughput, IntegrityChecker runs checks against the
FunctionDescription asynchronously using a ThreadPoolExecutor. When
IntegrityChecker.get_error_report is called, the async tasks are executed.
Darglint uses the Cocke–Younger–Kasami algorithm (CYK) to parse docstrings. The CYK algorithm allows parsing ambiguous grammars, which is useful for identifying stylistic errors.
The basic CYK algorithm consumes a grammar in Chomsky Normal Form (CNF), which
is inconvenient to write. Thankfully, grammars in Backus Normal Form (BNF) can
be automatically converted to CNF. Darglint's bin/ folder contains a utility,
bnf_to_cnf which takes a custom BNF representation and converts it to a Python
source file containing grammars.
The CYK algorithm has one of the best worst-case running times of parsers for
ambiguous grammars: O(n^3 * |G|), where n is the number of tokens and |G|
is the size of the grammar. However, it is still much slower than the previous
recursive descent LR(3) parser (by roughly an order of magnitude). To try to
decrease the run time, I've attempted to decrease the size of both n and |G|.
To decrease n, the tokens are run through a function, condense, which attempts
to merge tokens which are not keywords. Since, semantically, these are treated
the same, this decreases the runtime substantially.
To decrease the size of the grammar, |G|, any nodes which are not reachable
from the root are removed from the grammar.
The grammar resulting from the CYK algorithm is a binary tree, and is not very easy to consume. (See the example below.) Since the BNF representation has to be expanded during the conversion to CNF, it's not easy to know which specific node type will be associated with a desired target. For that reason, an extension to BNF was added to annotate a given branch.
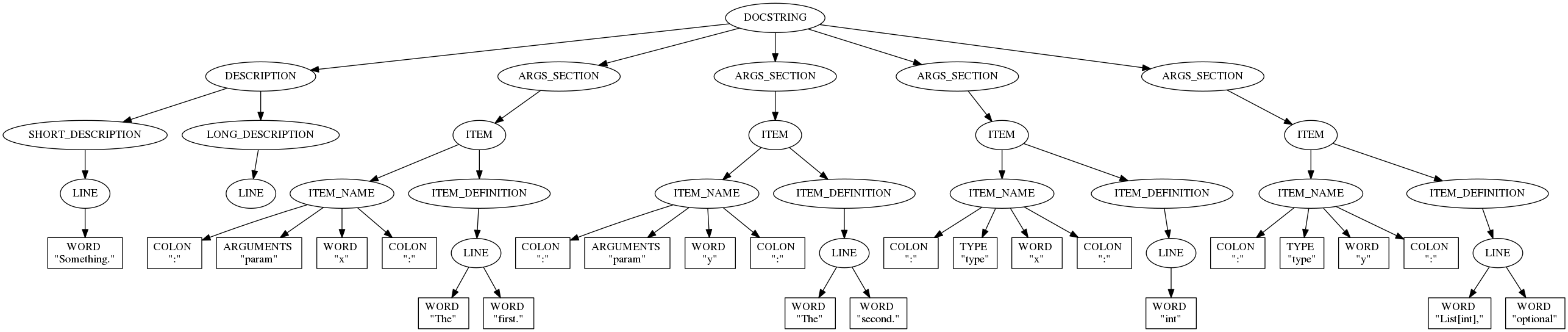
For example, an annotation was added to the head of an argument description in the Google arguments grammar:
<head-argument>
::= @ArgumentIdentifier
<indent> <ident> <colon>
| @ArgumentIdentifier
@ArgumentTypeIdentifier
<indent> <ident> <type-section-parens> <colon>
The annotations are preserved during the translation process, then cached when interpreting the AST. This allows for a single tree traversal, and simplifies finding a particular node.
Annotations are also used to identify erroneous constructs. Incorrect grammars are annotated with the error type. During interpretation of the AST, then, the errors are accumulated.